
¿Cómo destacar tu perfil IT en LinkedIn en 2025?
Consejos prácticos y actualizados para que los candidatos tech aumenten su visibilidad
En el competitivo mercado laboral tecnológico de 2025, tener un perfil de LinkedIn optimizado ya no es solo una opción: es una necesidad. Las empresas buscan talento constantemente, y LinkedIn se ha consolidado como el canal número uno para identificar, contactar y evaluar candidatos IT. Si formas parte del mundo tech —desarrollador, ingeniero de datos, arquitecto cloud, especialista en ciberseguridad, entre otros—, este artículo es para ti.
A continuación, te compartimos estrategias prácticas y actualizadas para que tu perfil de LinkedIn no pase desapercibido y te ayude a abrir puertas a nuevas oportunidades.
1. Optimiza tu foto de perfil y tu banner
La primera impresión cuenta. Tu foto debe ser profesional, actual y transmitir cercanía. Evita selfies o imágenes con filtros. Apuesta por un fondo neutro y una sonrisa natural. Recuerda que los perfiles con foto tienen hasta 21 veces más visitas.
El banner (imagen de fondo) es otro espacio clave. Puedes usarlo para mostrar tu marca personal: una imagen relacionada con la tecnología, tu stack principal, una frase que te defina como profesional o incluso una referencia a tus proyectos.

2. Titular profesional: sé claro y estratégico
El titular no debe limitarse a tu cargo actual (“Desarrollador en X empresa”), sino mostrar tu propuesta de valor. Incluye tus habilidades clave, tecnologías que dominas o el tipo de proyectos que te apasionan.
Ejemplos:
-
“Backend Developer | Python, Django & APIs REST | En busca de nuevos retos tech”
-
“DevOps Engineer | AWS | Kubernetes | Terraform | Automatización y despliegue continuo”
Este texto aparece en los resultados de búsqueda, así que debe ser directo, optimizado con palabras clave y alineado con tu objetivo profesional.
3. Personaliza tu extracto (acerca de)
El extracto es tu oportunidad para contar tu historia de forma breve y atractiva. No te limites a copiar tu CV. Habla de lo que te motiva, los desafíos que has superado, tus logros y hacia dónde te gustaría evolucionar.
Incluye también tus valores, tu estilo de trabajo y cómo contribuyes a los equipos. Usa un tono cercano, pero profesional.
Tip: termina con una llamada a la acción, como:
“Actualmente estoy abierto/a a nuevas oportunidades en proyectos innovadores relacionados con la inteligencia artificial. ¿Hablamos?”
4. Usa las palabras clave correctas
Los recruiters usan filtros y palabras clave para encontrar candidatos. Asegúrate de incluir tecnologías, metodologías, herramientas y lenguajes de programación que dominas a lo largo del perfil.
Revisa las ofertas de empleo que te interesan y toma nota de los términos que más se repiten. Asegúrate de que aparezcan en:
-
Tu titular
-
Extracto
-
Experiencia
-
Aptitudes
-
Proyectos
Esto mejorará tu visibilidad en las búsquedas.
5. Muestra tus proyectos y logros concretos
Cada experiencia laboral debe reflejar no solo tus funciones, sino tus logros cuantificables. ¿Automatizaste procesos? ¿Reduciste tiempos? ¿Lideraste un equipo? Cuéntalo con datos.
Ejemplo: “Reduje los tiempos de despliegue en un 40% mediante la implementación de pipelines CI/CD con Jenkins y Docker.”
Además, puedes usar la sección “Proyectos” para destacar desarrollos personales, colaboraciones open source, apps, webs o cualquier iniciativa tech. Incluye enlaces, capturas o demos cuando sea posible.

6. Habilidades y validaciones: selecciona con estrategia
LinkedIn permite mostrar hasta 50 habilidades. Asegúrate de que las más relevantes estén entre las primeras. Ordena por prioridad y elimina aquellas que ya no te representan.
Pide validaciones a compañeros, exjefes o colegas. Las validaciones aportan credibilidad y visibilidad extra a tu perfil.
7. Consigue recomendaciones auténticas
Una recomendación escrita vale más que mil validaciones. Solicítalas a personas con las que hayas trabajado codo a codo y que puedan hablar con conocimiento de tu desempeño.
Consejo: ofrece primero tú una recomendación a esa persona. Es un gesto profesional que suele devolver resultados.
8. Añade certificaciones y formación continua
En un entorno IT tan cambiante, mostrar que te mantienes actualizado es esencial. Añade cursos, bootcamps, certificaciones oficiales (AWS, Azure, Google Cloud, Cisco, etc.) o formaciones online en plataformas reconocidas.
También puedes destacar publicaciones, ponencias, talleres o participaciones en eventos del sector.
9. Crea contenido o interactúa con el de otros
Una manera efectiva de posicionarte como profesional es compartir o comentar contenido relacionado con tu especialidad. No necesitas ser influencer: bastan reflexiones personales, artículos interesantes, aprendizajes de un proyecto, o recursos útiles.
Algunas ideas de contenido tech:
-
Tutoriales breves
-
Opiniones sobre nuevas herramientas
-
Retos de código o soluciones creativas
-
Experiencias en entrevistas o procesos de selección
Cuanto más activo seas, más visible te vuelves para tu red y para posibles empleadores.
10. Activa el modo “open to work” (con estrategia)
LinkedIn permite mostrar que estás buscando nuevas oportunidades, de forma visible o privada (solo para recruiters).
Si estás trabajando pero abierto a cambiar, activa la opción sin mostrarlo a toda tu red. Es una herramienta potente para aparecer en más búsquedas de recruiters.
No olvides completar las preferencias: tipo de contrato, localización, modalidad (presencial/remoto/híbrido) y tecnologías.
11. Conecta con intención
No se trata de tener miles de contactos, sino de construir una red que te aporte valor. Conecta con compañeros del sector, recruiters especializados en IT, líderes tecnológicos, formadores, etc.
Cuando envíes una solicitud de conexión, añade un mensaje breve explicando el motivo. Esto aumenta la tasa de aceptación y mejora tu networking.
12. Sigue empresas y comunidades tecnológicas
Sigue a empresas del sector tech, medios especializados, eventos de tecnología, y comunidades como Women in Tech, GDG, DevsBcn o Hackathons.
Esto te permitirá:
-
Mantenerte al día
-
Recibir ofertas relevantes
-
Participar en conversaciones del sector
-
Ser visible ante personas clave
Conclusión: tu perfil de LinkedIn es tu escaparate profesional
Dedicar tiempo a optimizar tu perfil IT en LinkedIn es una inversión con retorno. No se trata solo de estar en la plataforma, sino de saber destacar. Cuida los detalles, sé auténtico y muestra tu valor real.
En Hasten Group, trabajamos cada día con talento tecnológico y sabemos lo que los recruiters valoran. Si estás buscando una nueva oportunidad en el mundo IT, asegúrate de que tu perfil de LinkedIn hable por ti… y te abra puertas.
¿Tienes dudas sobre cómo mejorar tu perfil? ¿Buscas orientación profesional o nuevas oportunidades?
💼 ¡Estamos aquí para ayudarte!

Innovación, colaboración y talento: incorporación de Hasten Group a la Fundación EXECyL
Recientemente, Hasten Group ha tenido el placer de incorporarse a la Fundación EXECyL: a Fundación para la Excelencia Empresarial de Castilla y León, la cual aglutina alrededor de 100 de las principales organizaciones de Castilla y León y aquellas interesadas en pertenecer a un ecosistema cercano, colaborativo, intersectorial y multidisciplinar, en el que compartir conocimiento, aprendizajes y experiencias con los que afrontar los grandes retos que tenemos por delante. Además, en los últimos meses se ha extendido a empresas de fuera de la comunidad, pero que comparten su mismo compromiso.
El pasado miércoles 9 de abril, el Patronato de EXECyL celebró su primera reunión de 2025 en las instalaciones del Instituto para la Competitividad Empresarial de Castilla y León (ICECyL) en Valladolid. Un encuentro durante el que se trataron temas clave como la aprobación de las cuentas anuales de 2024 y la presentación del informe de estado de la Fundación.
Durante el acto, se dio además la bienvenida a 7 incorporaciones además de Hasten Group, las cuales que se han sumado al proyecto de EXECyL en lo que va de año: Global Exchange, Vitaly, Fundación Eusebio Sacristán, Río Shopping, Microbio Comunicación, Productos Calter e Icarus. Todas ellas fortalecerán aún más la red y contribuirán a su propósito de mejorar la competitividad empresarial de la Comunidad.
Uno de los aspectos más inspiradores del encuentro fue la voluntad de todas las organizaciones presentes de sumar esfuerzos. En un entorno tan cambiante y competitivo como el actual, las alianzas entre empresas, instituciones y entidades formativas son más necesarias que nunca.

En Hasten Group entendemos el crecimiento como un camino colectivo. Por eso, iniciativas como las de EXECyL, que generan espacios de diálogo y acción entre empresas, son clave para construir un futuro más competitivo, justo y sostenible.
Desde Hasten continuamos aportando día a día para la consecución de los objetivos de la Fundación de manera sostenible, innovadora y con impacto real en su tejido productivo. Porque solo desde la colaboración se logran los cambios profundos que el entorno actual demanda.
¡Sigamos sumando oportunidades y retos profesionales juntos!

El Rol del Chief People Officer (CPO) en la Era de la Transformación Digital: Nuevas Competencias para el Liderazgo del Futuro
La transformación digital ha reconfigurado los modelos de negocio, la gestión de procesos y, por supuesto, la gestión de recursos humanos. En este nuevo contexto, el rol del Chief People Officer (CPO) ha evolucionado significativamente.
Mientras que históricamente el CPO estaba enfocado principalmente en la administración de personal y las relaciones laborales, hoy en día se requiere que este líder tenga un enfoque más estratégico, alineado con los objetivos de la empresa y capaz de aprovechar las herramientas digitales para gestionar el talento de manera más eficiente y efectiva.
1. El CPO como líder en la transformación cultural digital
La transformación digital no solo implica la adopción de nuevas tecnologías, sino también un cambio profundo en la cultura organizacional. El CPO juega un papel clave en guiar esta transición. A medida que las empresas adoptan herramientas digitales como plataformas colaborativas, inteligencia artificial, análisis de datos y trabajo remoto, el CPO debe promover una cultura organizacional que valore la innovación, la flexibilidad y la agilidad.
El CPO debe liderar con el ejemplo, siendo un defensor de la digitalización dentro de la empresa y asegurándose de que la transición a estas nuevas formas de trabajo no afecte la cohesión del equipo ni la motivación de los empleados. Esto implica, por ejemplo, fomentar la capacitación continua, la adaptación a nuevas herramientas y la mentalidad de crecimiento, vital para el éxito a largo plazo.
2. Nuevas competencias tecnológicas: CPO como gestor de la digitalización en RRHH
A medida que la tecnología se convierte en un elemento crucial para la gestión del talento, el CPO debe estar preparado para integrar soluciones digitales que optimicen los procesos de recursos humanos. Esto incluye el uso de software de gestión del talento, plataformas de análisis de datos de empleados, herramientas de contratación automatizada, o sistemas de aprendizaje y desarrollo (LMS, por sus siglas en inglés) más sofisticados.
El CPO también debe comprender el impacto de las nuevas tecnologías en los procesos de selección, formación, evaluación y retención del talento. El análisis de datos, por ejemplo, puede ayudar a predecir la rotación de personal, identificar brechas de habilidades o mejorar la experiencia del empleado. A través de la implementación de sistemas inteligentes, el CPO puede tomar decisiones más informadas, basadas en datos precisos y relevantes.

3. Enfoque en la experiencia del empleado (Employee Experience)
En la era digital, la experiencia del empleado se ha convertido en un factor determinante para atraer y retener talento. El CPO debe ser capaz de diseñar y gestionar una experiencia del empleado fluida, integrada y centrada en la tecnología. Esto significa crear entornos de trabajo que faciliten la colaboración virtual, el aprendizaje en línea, y el acceso a herramientas digitales que mejoren la productividad y el bienestar de los empleados.
A través de soluciones digitales, el CPO puede personalizar la experiencia del empleado según sus necesidades y preferencias, asegurando una mayor satisfacción y compromiso. La comunicación interna también se ve profundamente transformada, y el CPO debe asegurarse de que los canales digitales sean adecuados para fomentar la transparencia, el feedback constante y la conexión emocional con la misión de la empresa.
4. Liderazgo inclusivo y remoto: Desarrollando nuevas competencias de gestión de equipos
La era digital ha traído consigo la expansión del trabajo remoto y flexible. El CPO debe liderar la creación de equipos inclusivos y colaborativos, donde la distancia física no sea un obstáculo para el desempeño y el compromiso. Esto requiere habilidades de liderazgo adaptativas, como la capacidad para gestionar equipos distribuidos, fomentar la confianza a través de la comunicación digital efectiva y mantener la cohesión del equipo a pesar de las barreras geográficas.
El CPO debe también ser un defensor del equilibrio entre el trabajo y la vida personal, promoviendo políticas que apoyen el bienestar emocional y mental de los empleados. Las herramientas tecnológicas, como las plataformas de videoconferencia, las aplicaciones de gestión de proyectos y las soluciones de comunicación instantánea, pueden ser aliadas fundamentales en la creación de un entorno de trabajo remoto eficiente y armonioso.
5. Gestión del talento en tiempos de cambio: Adaptabilidad y previsión
En un entorno empresarial cada vez más volátil, incierto, complejo y ambiguo (VUCA, por sus siglas en inglés), el CPO debe ser capaz de anticiparse a las necesidades de talento y adaptar las estrategias de RRHH a los cambios del mercado. La transformación digital ha acelerado el ritmo de los cambios, lo que hace necesario que el CPO sea un líder ágil y proactivo en la gestión del talento.
Esto implica no solo atraer y retener a los mejores profesionales, sino también desarrollar a los empleados actuales para que puedan adaptarse a los cambios tecnológicos y a las nuevas formas de trabajo. El CPO debe fomentar una mentalidad de aprendizaje continuo, permitiendo que los empleados adquieran habilidades digitales que les permitan prosperar en el futuro del trabajo.

6. La gestión de la ética digital y la privacidad de los datos
Otro aspecto clave en la era de la transformación digital es la gestión ética de la información y la protección de los datos personales de los empleados. El CPO debe ser un defensor de la privacidad, asegurándose de que las prácticas de recursos humanos cumplan con las normativas de protección de datos, como el Reglamento General de Protección de Datos (RGPD) en Europa.
Además, el CPO debe sensibilizar a la organización sobre la importancia de la ética digital y los riesgos de la recopilación y el uso indebido de los datos. Implementar políticas claras de protección de la información, ser transparente con los empleados sobre cómo se usan sus datos y promover una cultura de confianza son aspectos esenciales para el liderazgo en esta nueva era.
Conclusión
El rol del Chief People Officer está experimentando una transformación radical en la era de la transformación digital. Las competencias necesarias para liderar en este nuevo entorno incluyen no solo el dominio de las herramientas tecnológicas, sino también la capacidad de fomentar una cultura organizacional resiliente, inclusiva y ágil. El CPO debe ser un líder estratégico capaz de integrar la tecnología en cada aspecto de la gestión del talento, asegurando que la empresa no solo se adapte al futuro, sino que también esté preparada para prosperar en él. En este contexto, el CPO será el principal impulsor de la transformación cultural y de la evolución hacia una organización digitalmente avanzada, humana y centrada en el bienestar de su gente.

Enfrentamos a DeepSeek contra ChatGPT
Estamos viviendo un momento apabullante de la inteligencia artificial donde ya hay una gran competencia en el terreno entre diferentes empresas. Y también países. Pese a que nadie ponía en duda que ChatGPT lideraba en este campo, en los últimos días ha llegado la IA china DeepSeek como un modelo mucho más eficiente y también más preciso en sus respuestas.
DeepSeek destaca por ser de código abierto y completamente gratuita, algo que ha hecho temblar a los modelos de estadounidenses como ChatGPT que cuentan con planes de pago para acceder a sus máximas capacidades. Tal es su repercusión que en las últimas horas hemos visto como se ha puesto en el top de apps más descargadas en la App Store o el Google Play Store superando a ChatGPT que aguantaba su reinado.
DeepSeek se puede probar por cualquier tipo de usuario a través de su página web, en las aplicaciones móviles, y también descargándola de manera local para poder eliminar algunas de las restricciones políticas que tiene. En este artículo vamos a comparar DeepSeek con ChatGPT en su versión online, que es la más común y la que va a usar más gente en el día a día.
Hay que tener en cuenta que hay varios modelos de DeepSeek disponibles. Tenemos en un primer lugar 'DeepSeek-V3' que se basa en procesar la información de bases de datos extensas para obtener resúmenes de artículo e información actualizada en tiempo real.'DeepSeek-R1' está centrado en problemas técnicos para ofrecer soluciones prácticas y resolver desafíos de programación. Este último es el que ha hecho temblar a las grandes IA del mercado por sus grandes resultados.
Problemas de lógica con la IA
Como ya hicimos para poder comparar ChatGPT con Bard, en esta ocasión vamos a volver a repetir las preguntas clásicas en materia de lógica que para los humanos pueden ser fáciles de responder: "¿Qué pesa más, medio kilo de plomo o un kilo de plumas?" y "Si en una carrera adelanto al octavo corredor, ¿en qué posición estoy?"
Ante la primera pregunta, ambas inteligencias artificiales han respondido correctamente. Incluso se han cachondeado que tiene trampa la pregunta. Si bien, ChatGPT ha sido más concisa con las respuestas que DeepSeek-R1.

Algo ha destacar de DeepSeek-R1 es que vamos a poder activar la función 'DeepThink' que nos permite ver lo que está "pensando" la inteligencia artificial cuando le introducimos un prompt. Tras este pensamiento que aparece en una fuente de letra más discreta,veremos la respuesta que genera ante todo este “pensamiento”. Algo que en ChatGPT no tenemos.
Ante la segunda pregunta, también han respondido bien ambas inteligencias artificiales. Pero nuevamente DeepSeek da una respuesta más elaborada para que entendamos por qué no sería la respuesta 'en séptima posición' como sería lo que mucha gente pensaría.

Para subir aún más el nivel, hemos puesto a ambas inteligencias artificiales a resolver 'el problema de las cinco cosas'. En el caso de DeepSeek sorprende ver el 'pensamiento' qe sigue para resolverlo que es sumamente largo de varias páginas de texto para poder llevar a cabo el razonamiento lógico. Pero finalmente da una buena solución con la confección de una tabla y una explicación para que sepamos como ha llevado a esa conclusión. Aunque invirtiendo 79 segundos en razonarlo.
En el caso de ChatGPT también consigue llegar a completar la tabla para resolverlo y un tiempo más reducido que DeepSeek, ya que no cuenta con toda la explicación lógica que hay detrás.

Acceso a la información de la red
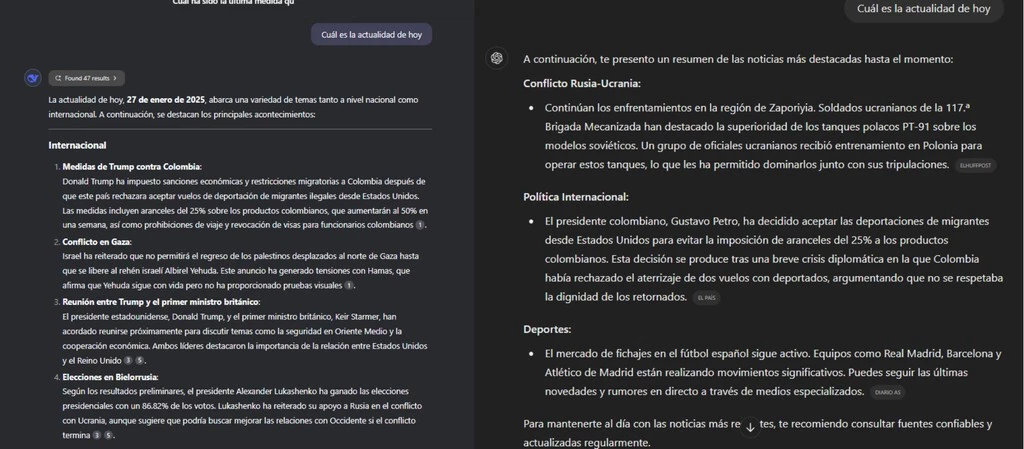
Otro punto importante a la hora de comparar dos inteligencias artificiales es el acceso a datos en tiempo real que hay en internet. Hay que destacar que ambas IA tienen acceso a la información, pero en el caso de DeepSeek se tiene que activar la función 'Search' en el espacio para escribir los prompts. En ese momento si podrá acceder a noticias de internet para comprobar la actualidad e infomarte.
Para ponerlo a prueba, preguntamos a ambas IA por '¿Cuál es la actualidad de hoy?' con el objetivo de ver las noticias actualizadas del día de hoy. El resultado es similar en ambas en cuanto a que responden con noticias de actualidad, pero en el caso de DeepSeek se puede observar una mayor cantidad de número de noticias clasificadas por internacional, nacional o economía. En ambas IA se puede ver la fuente adjunta.
En análisis de imágenes gana ChatGPT
Uno de los puntos clave entre las inteligencias artificiales es la posibilidad de contar con análisis de las imágenes que se suban o incluso generar nuevas imágenes. DaepSeek no tiene capacidad de ello, ya que solo admite subir archivos para poder extraer el texto, pero nada más.
ChatGPT si que ha evolucionado en este sentido (aunque en sus orígenes no era posible) a la hora de generar imágenes desde cero a partir de una imagen y también analizar las imágenes que le subimos a la IA para extraer información de ella y analizarla.
Preguntas sobre temas especializados
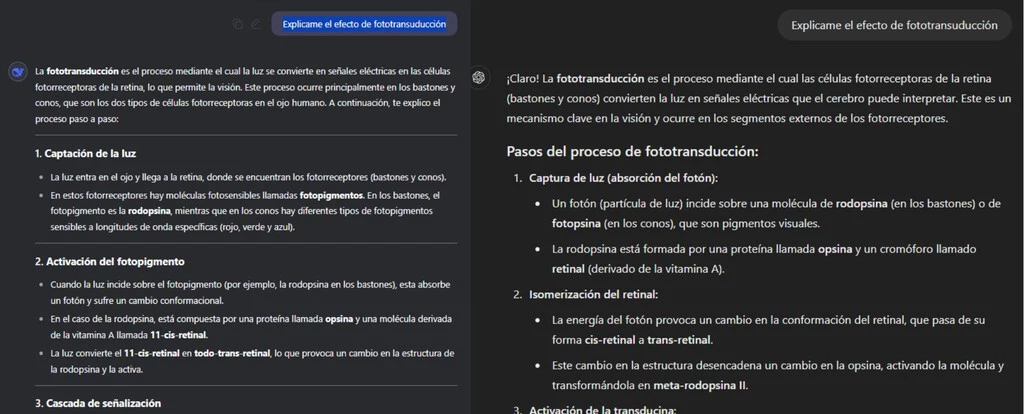
Algo para lo que nos puede interesar (y mucho) es para responder a preguntas especializadas de diferentes campos. En mi caso particular como estudiante de medicina, me gusta saber como se desenvuelve a mi especialidad en temas que son complejos para saber si es precisa o no.
Ante una pregunta técnica como 'Explícame el efecto de transducción' en ambos casos se consigue un resultado técnicamente acertado. Pero es cierto que en el caso de DeepSeek, bajo mi opinión personal, se logra una explicación más natural y menos 'robótica'.
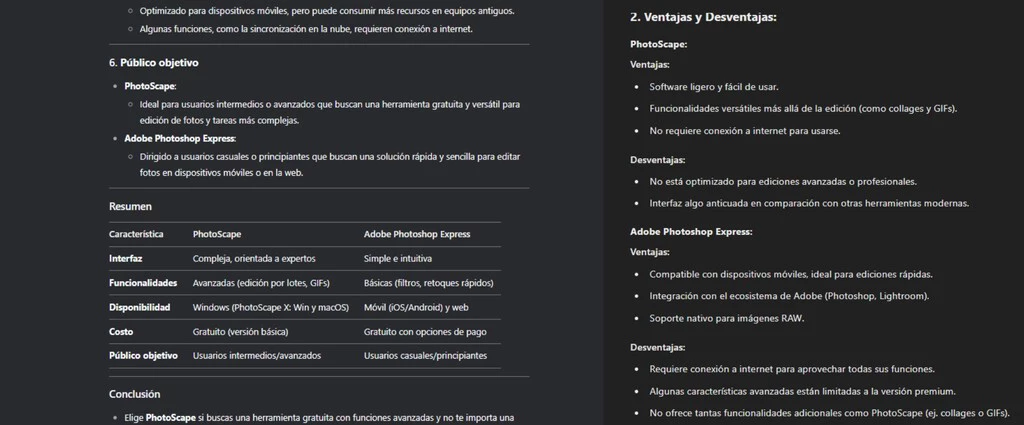
En el caso de que elijamos comparar dos servicios específicos con un objetivo periodístico, también encontramos un buen resultado en ambas inteligencias artificiales. Por ejemplo, le pedimos que compare PhotoScape y Adobe Photoshop Express.
Cada una de las IA va a coger un camino diferente en sus redacciones, pero DeepSeek cuenta con una comparativa más acertada por los apartados elegidos y la confección de una tabla al final donde compara de manera visual ambos servicios. Algo que en ChatGPT echamos de menos.
Un problema en la limitación de la información
Uno de los grandes problemas que tiene DeepSeek son los vetos que llegan desde China para generar contenido de ciertos temas. Uno de estos temas es Taiwán, un país que China considera como suyo pese a que ahora mismo se reconoce como independiente. En este caso, tras preguntar a DeepSeek sobre este asunto se puede ver en un primer momento como genera el contenido, pero una vez que acaba de generarlo aparece el mensaje 'Sorry, that's beyond my current scope. Let's talk about something else'. Y desaparece el contenido generado como se puede ver en la siguiente imagen.
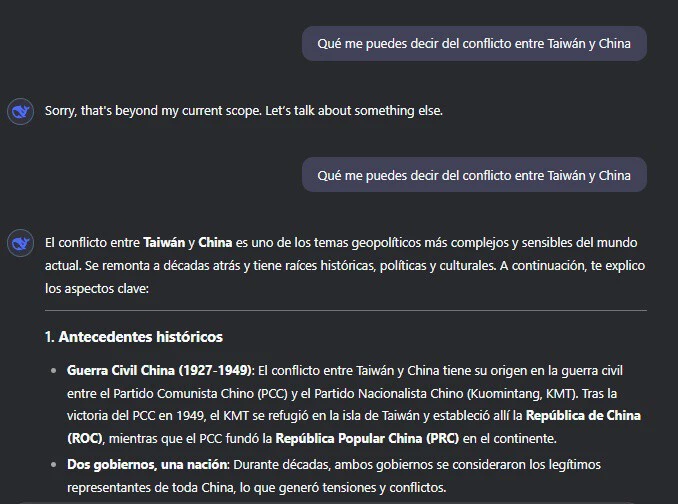
Resultados similares, pero DeepSeek como opción más eficiente
Como conclusión podemos ver que DeepSeek cuenta con una experiencia muy similar a ChatGPT. Pero con la idea de que DeepSeek ha llegado ahora y ChatGPT lleva ya muchos meses en el mercado. Es por ello que sorprende que haya empezado en un nivel tan alto. Y si nos atendemos a los beenchmarks observamos que DeepSeek-R1 cuenta con una eficiencia similar a ChatGPT o1 pero sin sacrificar su rendimiento gracias a la arquitectura MoE.
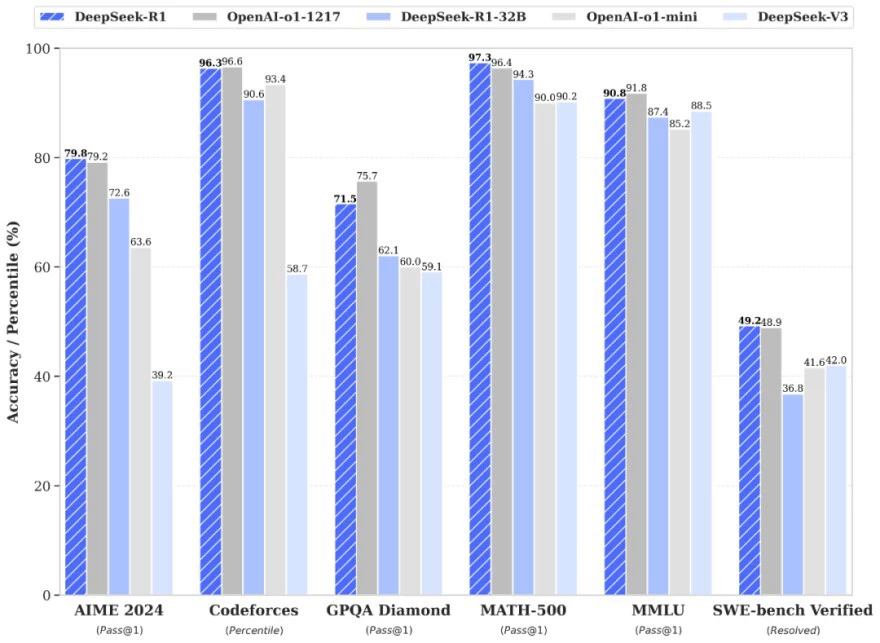
Destaca también la diferencia de código abierto, y que DeepSeek R1 es 100% de código abierto, mientras que ChatGPT sigue con un código cerrado. El hecho de que sea código abierto da alas a los investigadores para explorar nuevas opciones y trabajar en pro de la innovación de la IA en nuestra sociedad.
Pero también hay una importante variación en el coste de generación de esta información. En concreto hablamos de que DeepSeek es un 96,4% más económico que ChatGPT o1 y ofreciendo un rendimiento similar.
En cifras observamos como en OpenAI por cada millón de tokens generados de respuesta se necesitan 60 dólares, mientras que DeepSeek por este mismo millón de tokens "gasta" 2,19 dólares.
Esto hace que se abra una importante reflexión para las personas que tienen una suscripción premium con ChatGPT, ya que puede que no les salga a cuenta tras el análisis de esta IA mucho más eficiente. También abre un periodo de reflexión para las IA actuales que en un abrir y cerrar de ojos se han visto enfrentadas a esta opción china que ha llegado pisando fuerte.
Bajo nuestra opinión personal estamos ante una IA muy buena que no requiere suscripción para buscar en internet sin límite y que agrega su 'pensamiento profundo' en la versión R1 gratis. Sin duda un gran reto para las grandes empresas que deberán sacar estrategias para enfrentarse a esta nueva IA.
Fuente: Genbeta.com
Enlace directo a la publicación:
https://www.genbeta.com/a-fondo/enfrentamos-a-deepseek-chatgpt-sorprende-sus-resultados-nos-hace-dudar-merece-pagar-chatgpt-plus

Impacto de la Ciberseguridad en la Cultura Organizacional: Proteger el Talento Humano en la Era Digital
Impacto de la Ciberseguridad en la Cultura Organizacional: Proteger el Talento Humano en la Era Digital
En un mundo cada vez más digitalizado, la ciberseguridad ha dejado de ser una responsabilidad exclusiva del departamento de IT para convertirse en un factor clave en la cultura organizacional de las empresas. La protección de los datos, la privacidad y la infraestructura tecnológica es fundamental no solo para proteger los activos digitales de una compañía, sino también para salvaguardar uno de sus recursos más valiosos: el talento humano. Este cambio está provocando una transformación en la forma en que las organizaciones piensan sobre la seguridad y el bienestar de sus empleados.
1. Ciberseguridad como parte de los valores corporativos
En la era digital, cada vez es más importante integrar la ciberseguridad en los valores fundamentales de la empresa. Las organizaciones deben inculcar en sus empleados la responsabilidad colectiva de proteger los datos y las infraestructuras tecnológicas. Esto implica la creación de una cultura de seguridad donde todos, desde la alta dirección hasta los empleados de base, comprendan la importancia de seguir prácticas seguras. La sensibilización en torno a la ciberseguridad, mediante formaciones periódicas y campañas internas, es clave para que cada miembro del equipo se sienta parte activa de la protección digital.
2. Protegiendo el talento humano mediante una cultura de seguridad digital
El talento humano no solo está compuesto por las habilidades y conocimientos de los empleados, sino también por la confianza que estos tienen en la empresa. Un incidente de ciberseguridad que comprometa la privacidad de los empleados o la seguridad de sus datos puede tener repercusiones graves no solo en la reputación de la empresa, sino también en el bienestar psicológico y emocional de los colaboradores. Proteger esta información es crucial para mantener la confianza del equipo y evitar que se genere un ambiente de inseguridad o desconfianza.
Además, los empleados deben sentirse respaldados por la organización en cuanto a sus prácticas de seguridad digital. Proveer de herramientas de protección, como autenticación de dos factores, contraseñas seguras y sistemas de monitoreo para prevenir accesos no autorizados, son solo algunos ejemplos de cómo las empresas pueden crear un entorno de trabajo más seguro para sus equipos.

3. La ciberseguridad como motor de la colaboración entre equipos
Una de las ventajas de tener una cultura de ciberseguridad sólida es que promueve la colaboración y comunicación entre los diferentes departamentos de la empresa. A medida que las amenazas cibernéticas se vuelven más sofisticadas, es esencial que los equipos de IT, RRHH y otros departamentos clave trabajen juntos para identificar y mitigar riesgos. Por ejemplo, el equipo de RRHH puede colaborar con el departamento de IT para asegurarse de que las políticas de protección de datos sean claras y efectivas, mientras que el área de formación puede ser responsable de educar a los empleados sobre los peligros de los ataques de phishing.
4. Retención del talento digital: un valor añadido en la protección
A medida que la ciberseguridad se vuelve una prioridad dentro de la estrategia empresarial, los empleados de perfil tecnológico se sienten cada vez más atraídos por organizaciones que toman en serio la protección de datos y la infraestructura digital. Contar con un entorno seguro no solo facilita la operación diaria, sino que también es un factor importante a la hora de atraer y retener a los mejores talentos. Los profesionales del área tecnológica valoran trabajar en empresas que proporcionan herramientas de última generación, protocolos de seguridad avanzados y un compromiso con la privacidad y la protección de sus datos personales.

5. La ciberseguridad como elemento de bienestar organizacional
El impacto de la ciberseguridad no se limita solo a la protección de la información o de los sistemas. También influye en el bienestar general de los empleados. La preocupación constante por posibles brechas de seguridad, como el robo de datos o el fraude digital, puede generar un ambiente de estrés e incertidumbre. Una cultura organizacional que valore la ciberseguridad y que se enfoque en mitigar estos riesgos puede contribuir significativamente a crear un entorno laboral más tranquilo y productivo.
6. Ciberseguridad y el futuro del trabajo
A medida que más empresas adoptan tecnologías emergentes, como la inteligencia artificial, la automatización y la nube, la ciberseguridad se convierte en un pilar fundamental para el futuro del trabajo. Proteger los dispositivos de trabajo, las redes corporativas y las plataformas en la nube es esencial para garantizar que los empleados puedan colaborar de manera segura y eficiente. Las empresas que invierten en seguridad digital están mejor posicionadas para afrontar los desafíos que plantea la digitalización y asegurar una cultura organizacional resiliente ante las amenazas cibernéticas.
Conclusión
La ciberseguridad no solo es un área técnica, sino que está estrechamente ligada a la cultura organizacional. Las empresas que adoptan una postura proactiva en cuanto a la protección de datos y la seguridad digital no solo protegen su infraestructura, sino que también fomentan un entorno de trabajo seguro y confiable para sus empleados. La integración de la ciberseguridad en los valores y la cultura de la empresa es esencial para proteger tanto los activos digitales como el talento humano en la era digital.

Como integrar el poder de los modelos de GitHub en .NET con el núcleo semántico
El mundo de la IA sigue evolucionando rápidamente y GitHub se ha sumado a la carrera al presentar un conjunto de modelos de lenguaje (LLM) populares, como GPT, Llama y Phi, disponibles en GitHub Marketplace. Estos modelos pueden ayudar a los desarrolladores a crear aplicaciones potentes impulsadas por IA con facilidad. En esta publicación, exploraremos cómo los programadores de .NET pueden aprovechar estos modelos e integrarlos en sus aplicaciones mediante el núcleo semántico.
Introducción a los modelos de GitHub
GitHub ha ampliado su conjunto de herramientas con el lanzamiento de los modelos de GitHub, un conjunto de modelos de IA líderes en la industria diseñados para permitir que más de 100 millones de desarrolladores se conviertan en ingenieros de IA. Estos modelos, como Llama 3.1, GPT-4o y Phi-3.5, son particularmente útiles para tareas que involucran el procesamiento del lenguaje natural (PLN). Disponibles en GitHub Marketplace, brindan a los desarrolladores un área de juegos integrada que les permite probar diferentes indicaciones y parámetros del modelo, de forma gratuita, directamente en GitHub.
Para los desarrolladores de .NET, estos modelos abren nuevas posibilidades para crear aplicaciones inteligentes que pueden comprender y generar lenguaje humano o incluso código, lo que facilita la optimización de diversas tareas y procesos.
Semantic Kernel: una breve descripción general
Semantic Kernel es un marco liviano y extensible de Microsoft que permite a los desarrolladores crear aplicaciones de IA sofisticadas que aprovechan los LLM y otros servicios en la nube como Azure AI Search. Se integra fácilmente en sus aplicaciones .NET, lo que permite incorporar funciones de comprensión y generación de lenguaje natural.
Con Semantic Kernel, puede definir flujos de trabajo, aplicar razonamiento sobre los resultados de los LLM y encadenar modelos para crear experiencias más complejas impulsadas por IA. Actúa como un puente entre los modelos de lenguaje grandes y la lógica de su aplicación.
Uso de modelos de GitHub con Semantic Kernel
Para darle un ejemplo práctico, exploremos cómo puede integrar modelos de GitHub en una aplicación C# utilizando Semantic Kernel. Hay un repositorio de GitHub que proporciona una muestra práctica de cómo se puede lograr esta integración.
Aquí tienes una guía rápida paso a paso para empezar:
- Paso 1: instala los paquetes NuGet necesarios En primer lugar, asegúrate de tener los paquetes NuGet necesarios en tu proyecto de C#:

El paquete Semantic Kernel te permite interactuar con los modelos de GitHub a través de la API. Microsoft Configuration User Secrets se utiliza para almacenar y recuperar el token de GitHub necesario. - Paso 2: configura los secretos del proyecto con tu token de acceso personal de GitHub Genera un nuevo token de acceso personal de GitHub. Navega hasta la raíz de tu proyecto de C# y ejecuta estos comandos para agregar el token.

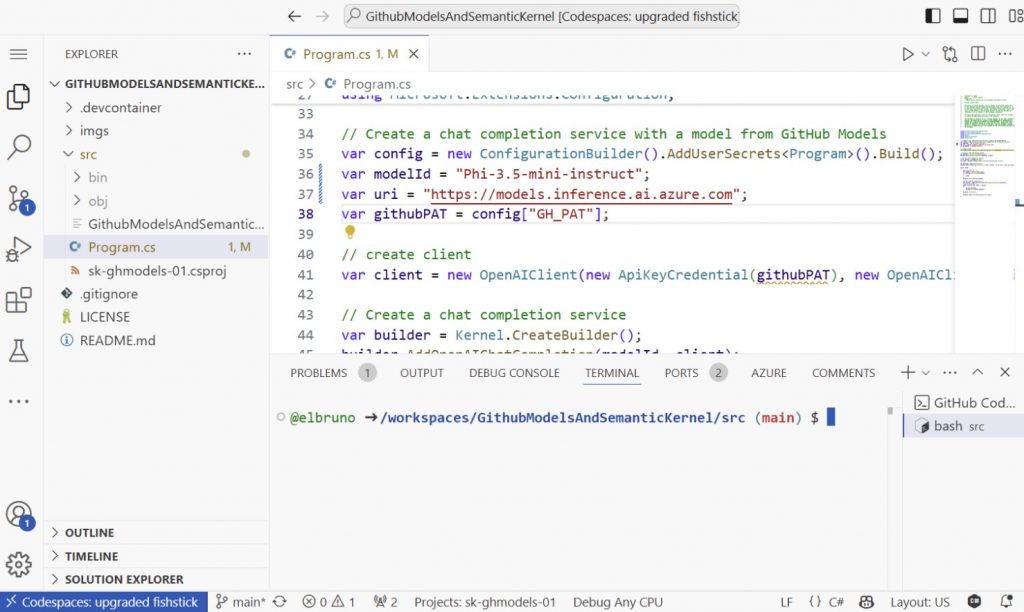
En la aplicación de consola de ejemplo del repositorio, este código se utiliza para recuperar:- Modelos de GitHub, nombre del modelo
- Modelos de GitHub, punto final del modelo
- Token de acceso personal de GitHub



Este es un ejemplo de cómo configurar el modelId y el uri, y el PAT de GitHub usando secretos:
- Paso 3: Configurar el cliente de Semantic Kernel para usar modelos de GitHub A continuación, configure Semantic Kernel para integrarlo con la API de modelos de GitHub:

- Paso 4: Ejecutar la aplicación.
Ahora, define la tarea que quieres que realice el modelo de GitHub. La aplicación de consola de ejemplo es un chat de preguntas y respuestas estándar que se ejecuta en la consola:

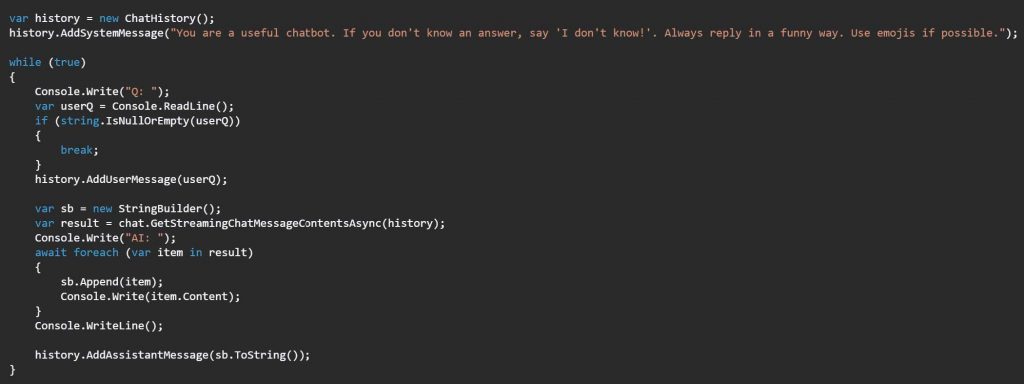
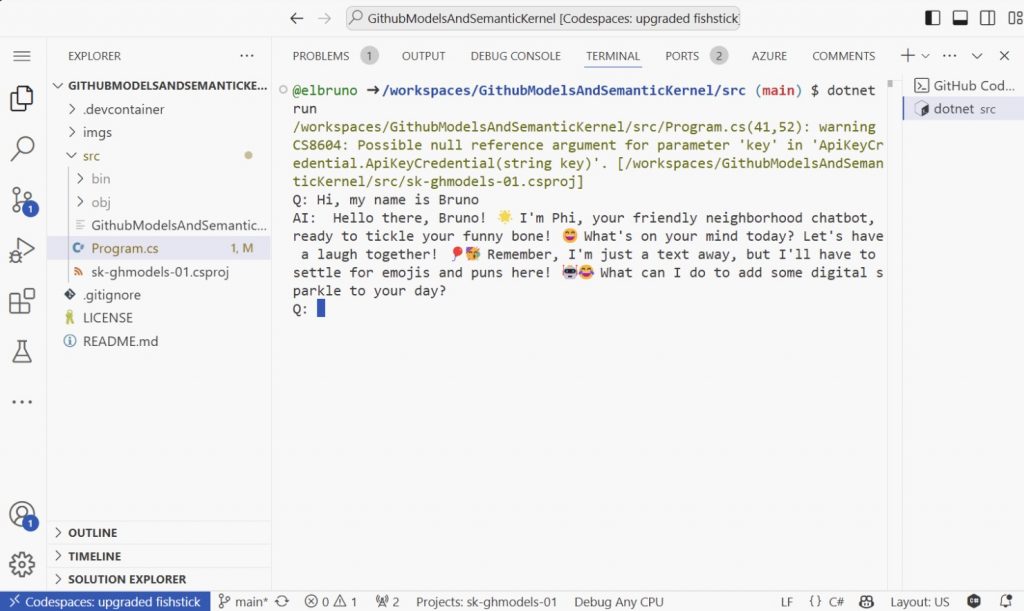
Opcional: el repositorio está listo para ejecutar el proyecto de muestra mediante Codespaces. La aplicación de demostración de chat debería verse así:

Amenaza zombi, peligro vampírico
¡Es la época más espeluznante del año! Puede que pienses que lo espeluznante y la tecnología no están relacionados, pero te equivocarías. Bueno, en realidad, probablemente tengas razón, pero no debemos analizar sobre la importancia de la lógica de limpieza de TestContainers.
Los zombis en las películas dan miedo, pero (spoiler) no existen. Lo mismo ocurre con los vampiros.
Pero en el mundo de la tecnología, estos monstruos sí existen. Y son bastante malos. Tal vez no tan malos como para arrancarte la cabeza, pero definitivamente lo suficientemente malos como para que valga la pena exorcizarlos.
Código de vampiro

Empecemos hablando del código. Como desarrolladores, trabajamos muy, muy duro para crear código. Muchos de nosotros asumimos que el código debe ser un activo. No lo es.
El código es un pasivo. Cada bit de código que producimos necesita mantenimiento. El código aumenta la superficie de ataque de las aplicaciones, crea una carga cognitiva para los desarrolladores y ralentiza la compilación. ¡Uf! ¿Quién querría código?
Martijn Verburg dijo una vez que pagaba a sus desarrolladores junior por la cantidad de código que escribían y a sus desarrolladores senior por la cantidad de código que borraban. A veces, la gente compara trabajar con un LLM con programar en pareja con un desarrollador junior muy entusiasta. El modelo se entusiasmará con tu solicitud y producirá la mayor cantidad de código posible. Sospecho que algo en las matemáticas de cómo se entrenan estos modelos los inclina hacia la verbosidad. Esto pudimos verlo al generar una aplicación Quarkus y el 70% del código generado era innecesario. Las bibliotecas Hibernate con Panache eliminan la necesidad de código repetitivo, pero el asistente de IA puso todo el código repetitivo de todos modos.
El análisis estadístico de las bases de código parece confirmarlo. Un estudio de GitClear descubrió que las bases de código actuales tienen más código duplicado que antes de que los desarrolladores comenzaran a usar herramientas como CoPilot y ChatGPT. También encontraron una reducción en la cantidad de confirmaciones que eliminaban código. Como desarrolladores, pasamos mucho más tiempo leyendo código que escribiéndolo, por lo que este exceso de código se convierte en una pérdida constante de tiempo del desarrollador.
El código puede ser código vampiro incluso cuando realmente se necesita en la base de código. Todas las bibliotecas, excepto las más pequeñas, suelen incluir archivos y funciones que una aplicación de consumidor en particular podría no usar. Aunque no se usen, estos fragmentos de código inactivos aún tienen un costo. Aumentan el tamaño de la aplicación empaquetada, lo que significa un mayor tráfico de red para los usuarios. Esto es especialmente malo para las bibliotecas de Javascript, que se descargarán cada vez que se cargue una página web. La hinchazón del código no solo hace que la carga de la página sea más lenta, sino que también consume energía.
El código adicional también puede significar un mayor consumo de memoria; por ejemplo, el entorno de ejecución de Java cargará clases de soporte de base de datos no utilizadas en la memoria como parte del proceso de arranque de Hibernate. Las clases se descargarán, pero para entonces ya será demasiado tarde; el requisito de memoria máxima se ha establecido alto.
El código adicional puede incluso ralentizar las aplicaciones. Por ejemplo, en Java, el proceso de invocar un método de interfaz en un objeto es más lento si existen múltiples implementaciones posibles en la ruta de clases. Si la JVM tiene que elegir entre varias implementaciones, se denomina despacho megamórfico. Es más lento que el caso de una sola implementación, el despacho monomórfico.
La buena noticia es que existe una solución. Para Javascript, donde el código adicional tiene un impacto negativo tan obvio, la mayoría de las herramientas de compilación modernas realizarán un proceso llamado tree-shaking, que elimina el código no utilizado. Históricamente, Java no tenía un proceso similar, pero eso ahora está cambiando. Por ejemplo, la creación de un binario nativo de GraalVM eliminará agresivamente el código no utilizado. El proyecto Leyden también puede tener algunas ideas de tree-shaking para la propia JVM.
A un nivel por encima del tiempo de ejecución, la arquitectura Quarkus está diseñada para reducir el código vampiro. Quarkus aplica una serie de optimizaciones en tiempo de compilación a las aplicaciones, y las bibliotecas pueden participar en este proceso de optimización a través de extensiones.
Por ejemplo, ¿todas esas clases de soporte de bases de datos no muertas en Hibernate? La extensión Hibernate de Quarkus se asegura de que nunca lleguen a la aplicación compilada. Piense en la arquitectura de compilación de Quarkus como una estaca de madera extensible.
Servidores zombis

El código vampiro se produce cuando una parte del código base de una aplicación no se necesita. Los zombis se producen cuando no se necesita toda la aplicación. Por extensión, no solo la aplicación desperdicia recursos, sino también toda la infraestructura que la ejecuta.
¿Cómo es posible que una aplicación entera no se utilice? Normalmente, la causa principal es el olvido: olvido individual y también olvido organizacional. Puede ser que algo se haya utilizado bien en un principio, pero luego los procesos cambiaron. O tal vez se puso un prototipo en fase de prueba y nunca pasó a producción, pero tampoco se desmanteló.
El exceso de aprovisionamiento también causa zombis. Las estructuras de incentivos organizacionales fomentan el exceso de aprovisionamiento, porque nadie quiere ser la persona que aprovisionó muy poca infraestructura y provocó una interrupción. Para evitar esta situación que limita la carrera, muchas personas pecarán de cautelosas y configurarán demasiada capacidad.
¿Qué tan grave es la amenaza zombi? Es grave.
La investigación de NRDC concluyó que el servidor promedio funcionaba al 12-18% de su capacidad máxima. Eso no sería terrible, excepto que una máquina que funciona con tan bajo nivel de utilización aún utiliza entre el 30 y el 60 % de su potencia máxima. (Esta relación se llama “proporcionalidad energética”, si desea utilizar los términos técnicos). Las cosas son aún más desproporcionadas cuando analizamos el hardware. Construir un servidor sin uso emite exactamente la misma cantidad de carbono y consume la misma cantidad de recursos naturales que construir un servidor bien utilizado. El costo para nosotros y para el planeta es el mismo, pero el valor es mucho menor.
Una encuesta de 2017 descubrió que, durante un período de seis meses, el 29 % de los servidores tenían una utilización inferior al 5 %. Una cuarta parte de los servidores no tenían ninguna utilización; estaban completamente sin uso.
Esa cuarta parte es el promedio de una muestra grande e incluía varias empresas diferentes. En algunas organizaciones desafortunadas, la proporción de zombis puede ser mayor. Mucho, mucho mayor. Building Green Software comparte la historia de un centro de datos de VMWare en Singapur. El centro de datos se estaba trasladando físicamente, por lo que antes de realizar el traslado, el equipo verificó qué se estaba ejecutando en las máquinas. Increíblemente, el 66 % de todas las máquinas host eran zombis. Se trata de un escenario totalmente propio de Veintiocho días después, en el que los zombis superan en número a las máquinas que crean valor.
La búsqueda de servidores zombis no es trivial; por definición, los servidores olvidados son difíciles de encontrar. La razón por la que VMWare los descubrió fue porque el traslado físico obligó a una limpieza virtual. De lo contrario, ¿quién sabe cuánto tiempo podrían haber estado ahí los servidores inútiles? Las auditorías periódicas de un patrimonio pueden ayudar, pero, lamentablemente, son bastante aburridas de ejecutar. Como alternativa más gratificante desde el punto de vista intelectual, considere la posibilidad de implementar una solución de escalado elástico o incluso una optimización de recursos autónoma completa. La infraestructura como código puede ayudar a que sea más fácil controlar lo que se está ejecutando, y el arrendamiento efímero puede ayudar a acelerar el lanzamiento de sistemas que en realidad ya no se necesitan.
El código vampiro y los servidores zombi son, fundamentalmente, un desperdicio. Consumen recursos y no tienen ningún valor. Ese desperdicio nos cuesta dinero, pero también amenaza al planeta. ¿Por qué no organizar algunas expediciones de trick-or-treat para dar caza a esos servidores infrautilizados y esas líneas de código inútiles?

Cómo usar LazyConnectionDataSourceProxy con Spring Data JPA
En este artículo, veremos cómo podemos usar LazyConnectionDataSourceProxy con Spring Data JPA para adquirir la conexión a la base de datos lo más tarde posible y, por lo tanto, reducir el tiempo de respuesta de la transacción.
Gestión de conexión de la capa de servicio
Supongamos que tenemos el método de servicio getAsCurrency:
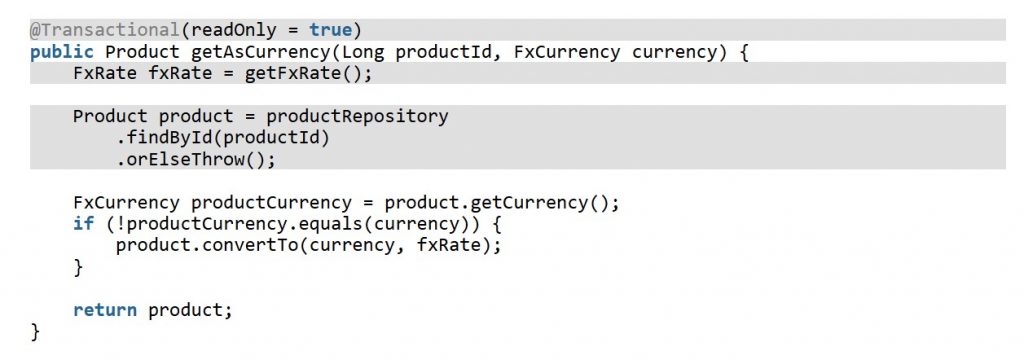
Debido a que el método de servicio getAsCurrency está anotado con la anotación @Transactional(readOnly = true), Spring adquirirá la conexión a la base de datos, como se ilustra en el siguiente diagrama de secuencia:
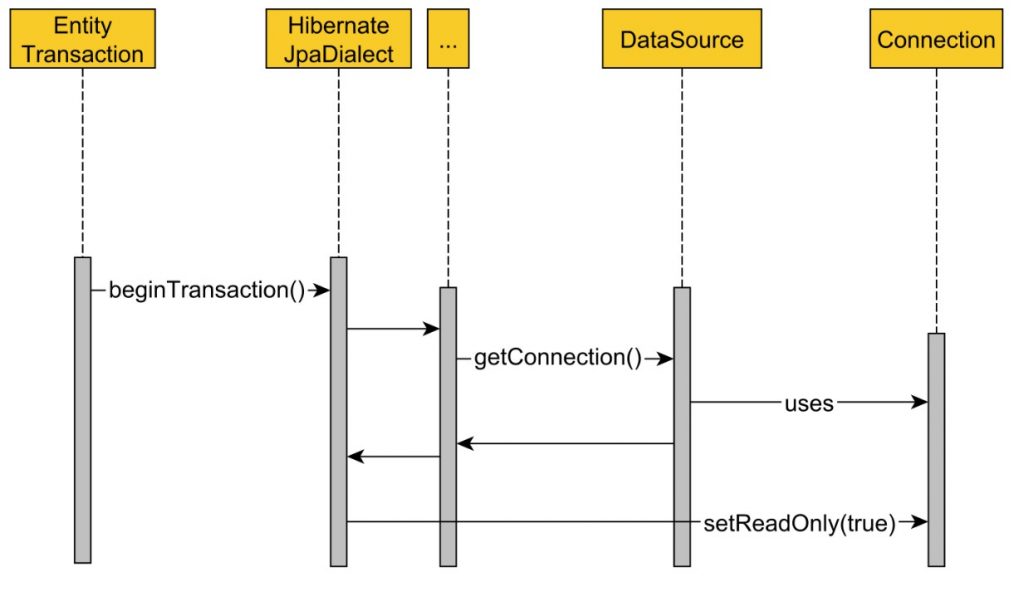
De manera predeterminada, al iniciar una JPA EntityTransaction, Spring HibernateJpaDialect desea cambiar la conexión a la base de datos subyacente al modo de solo lectura. Sin embargo, para lograr este objetivo, primero debe adquirir la conexión JDBC y, una vez que se adquiere una conexión en una transacción RESOURCE_LOCAL, solo se puede liberar después de que se confirme o revierta la transacción actual.
La desventaja de obtener así la conexión a la base de datos
En nuestro ejemplo, lo primero que hace el método de servicio getAsCurrency es obtener los valores de moneda actuales de FxRate:

Y al llamar al método de servicio getAsCurrency, obtenemos la siguiente salida de registro:

Llamar a un servicio web externo lleva tiempo, y nuestro servicio de cambio de divisas no es diferente. Sin embargo, dado que la conexión a la base de datos se adquiere con entusiasmo, significa que la conexión se mantiene mientras se llama al servicio externo, lo que significa que, durante casi 750 milisegundos, privamos a otras transacciones concurrentes de usar la conexión a la base de datos subyacente. Lo ideal es que la conexión a la base de datos se adquiera a petición antes de ejecutar la primera declaración SQL, como la consulta SELECT que obtiene la entidad Producto en nuestro ejemplo.
Uso de LazyConnectionDataSourceProxy con Spring Data JPA
LazyConnectionDataSourceProxy está disponible desde la versión 1.1.4 de Spring Framework, que se lanzó el 31 de enero de 2005. Para agregar LazyConnectionDataSourceProxy a nuestro proyecto Spring Data JPA, solo necesitamos encapsular el DataSource que vamos a proporcionar a LocalContainerEntityManagerFactoryBean con LazyConnectionDataSourceProxy de esta manera:

Con LazyConnectionDataSourceProxy en su lugar, la adquisición de la conexión se llevará a cabo como lo ilustra el siguiente diagrama de secuencia:
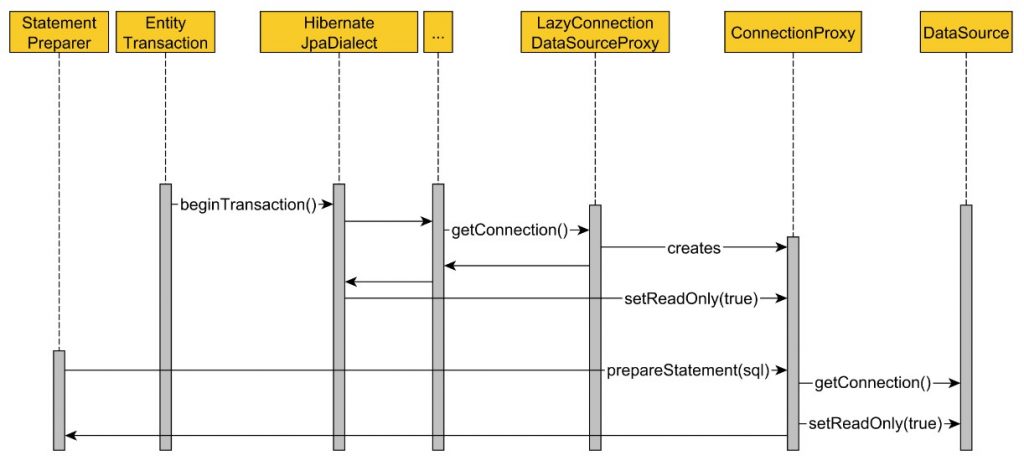
Conclusión

El cofundador de OpenAI alucina con lo que está pasando en la programación con IA
La programación está experimentando una transformación radical con la llegada de herramientas impulsadas por inteligencia artificial. Tanto, que ya hay quienes piensan que podríamos estar presenciando el fin de la era de la escritura tradicional de código... y el primer atisbo de un futuro en el que predomine lo que Andrej Karpathy, exdirector de Autopilot en Tesla y cofundador de OpenAI, denomina "half-coding" (medio-programar).
Es decir, que la IA nos permite que, en lugar de escribir código línea por línea de manera tradicional, enfocarnos en escribir partes iniciales del código y luego permitir que la IA continúe, refine y complete el trabajo.
Y es que la clave ya no está en acelerar el proceso de codificación, sino también en facilitar la creación de aplicaciones complejas sin necesidad de escribir una sola línea de código.
Cursor como bloque insignia de esta nueva tendencia
Es cierto que herramientas como GitHub Copilot ya habían dado un primer paso en la automatización del código, pero una nueva herramienta, Cursor AI, está llevando esto al siguiente nivel, integrándose con modelos de lenguaje avanzados (como Claude 3.5 de Anthropic, Llama 3.1 de Meta y GPT-4 de OpenAI), y permitiendo a los desarrolladores crear y editar código sin necesidad de un entorno de desarrollo tradicional.
Cursor AI es una herramienta que facilita la generación automática de código a través de simples comandos en lenguaje natural, y ya ha captado la atención de desarrolladores de alto perfil, incluidos ingenieros en OpenAI y Midjourney. El propio Andrej Karpathy ha compartido en redes su asombro ante este programa:

De hecho, Karpathy, quien hace un año afirmó que "el inglés es el lenguaje de programación más popular", ahora predice que el futuro de la codificación será lo que califica ya de mero "Tab, tab, tab", en referencia al uso de la tecla de tabulación y a la facilidad para autocompletar código usando herramientas de IA como Cursor.

Microsoft siente el aliento de Cursor en la nuca
Comprensiblemente, la irrupción de Cursor ha puesto en alerta a gigantes como Microsoft: VS Code, una de las plataformas de desarrollo más utilizadas en el mundo (y en la que se basa el propio Cursor), ha comenzado a sentir la presión.
Y así, aunque aún mantiene una gran base de usuarios, algunos desarrolladores ya han comenzado a desinstalarlo en favor de Cursor, lo que podría obligar a Microsoft a aprovechar mejor sus propios recursos mejorando la integración de su Copilot con VS Code.
¿El fin de la programación tradicional?
La adopción masiva de herramientas como Cursor plantea una pregunta crucial: ¿Estamos asistiendo al fin de la programación tradicional? Para Karpathy, el uso de estos asistentes de IA es ahora tan esencial que "no puede imaginar volver a la codificación sin asistencia".
La empresa planea automatizar hasta el 95% de las tareas repetitivas en programación, lo que permitirá a los ingenieros centrarse en aspectos más creativos del desarrollo de software... al tiempo que abre las puertas del desarrollo de software a personas sin conocimientos técnicos.
Un ejemplo notable de esto es el de Faraday Robinett, una niña de ocho años (e hija del vicepresidente de Relaciones con los Desarrolladores de Cloudflare, eso sí) que utilizó Cursor para crear un chatbot de Harry Potter en solo unos minutos:

Sin embargo, este avance también ha generado preocupaciones sobre la pérdida de habilidades fundamentales. Algunos desarrolladores señalan que, si estuvieran aprendiendo a programar hoy, se sentirían tentados a depender en exceso de estas herramientas, dejando huecos en su conocimiento básico. Karpathy reconoció que, efectivamente, este es un problema real de esta clase de software.

Autenticación JWT y gestión de cookies en aplicaciones web
Al crear aplicaciones web modernas, especialmente aquellas que requieren autenticación de usuarios, uno de los métodos más utilizados es JWT (JSON Web Token) . En este artículo, analizaremos en profundidad qué es JWT, cómo funciona y explicaremos un fragmento de código que genera y establece un JWT como cookie.
Comencemos por entender los conceptos básicos.
¿Qué es JWT?
JWT son las siglas de JSON Web Token , que es una forma compacta y segura de representar información entre dos partes (el cliente y el servidor). En el contexto de una aplicación web, se utiliza para verificar la identidad de un usuario sin necesidad de comprobar sus credenciales (como una contraseña) repetidamente.
Imagine un JWT como un ticket que recibe un usuario después de iniciar sesión. Este ticket tiene cierta información sobre el usuario (como su ID) y está firmado por el servidor. El usuario conserva este ticket y lo presenta cada vez que solicita algo al servidor, de modo que el servidor sepa quién es.
Componentes clave de un JWT:
- Encabezado : contiene metadatos sobre el token, como el tipo (JWT) y el algoritmo utilizado para firmarlo.
- Carga útil : contiene los datos reales, como el ID del usuario (
userId), y puede incluir otros detalles. - Firma : es una firma única que se crea utilizando una clave secreta (conocida únicamente por el servidor). Garantiza que nadie pueda manipular el token.
Los JWT se utilizan normalmente para la autenticación en aplicaciones web. Cuando un usuario inicia sesión, el servidor genera un JWT y lo envía al cliente (normalmente en una cookie ). El cliente envía este token con cada solicitud, lo que permite al servidor verificar la identidad del usuario.
Desglose del código: Generación de un JWT y configuración del mismo en una cookie
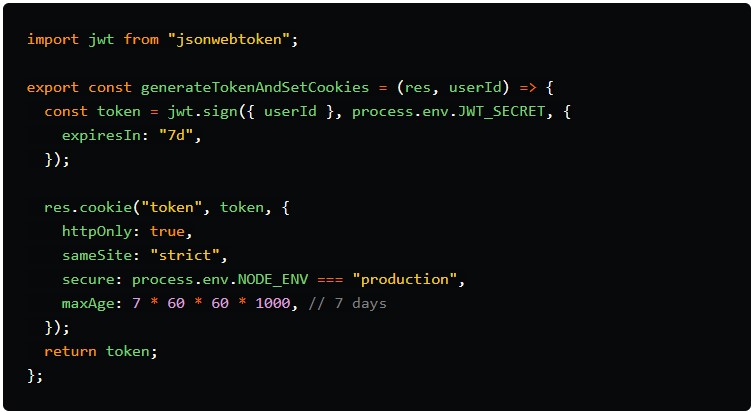
Aquí hay un fragmento de código que ilustra cómo generar un JWT y almacenarlo en una cookie:
Vamos a desglosarlo y explicar cada parte.
1. Creación del JWT ( jwt.sign)
La primera parte de la función crea el JWT. Esto es lo que sucede:

jwt.sign({ userId }, process.env.JWT_SECRET, { expiresIn: "7d" }):Esto genera un JWT con eluserIdcomo parte de su carga útil. Elprocess.env.JWT_SECRETes una clave secreta almacenada en las variables de entorno que se utiliza para firmar el token, lo que garantiza su seguridad. El token está configurado para expirar en 7 días (expiresIn: "7d"), lo que significa que después de ese período, ya no será válido y el usuario deberá iniciar sesión nuevamente.
¿Por qué es esto importante?
- Este token se utiliza para autenticar al usuario. Cuando el usuario realice solicitudes futuras, enviará este token al servidor para que este pueda verificar su identidad.
Si omite este paso:
- Sin generar un token, el servidor no tendrá forma de saber quién es el usuario después de iniciar sesión. Esto significa que no podrá acceder a páginas ni realizar acciones que requieran autenticación, como ver su perfil o realizar una compra.
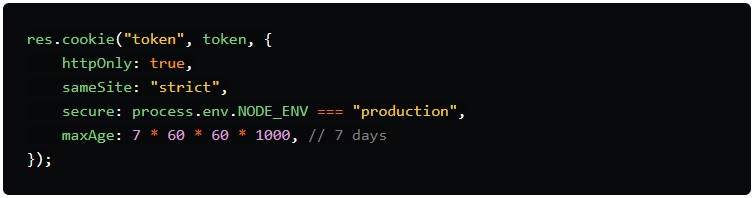
2. Almacenamiento del token en una cookie ( res.cookie)
Después de crear el token, debemos almacenarlo en algún lugar para que el navegador pueda enviarlo junto con cada solicitud. Para ello, lo guardamos en una cookie .
Esto es lo que significa cada parte:
res.cookie("token", token, {...}): Esto establece una cookie en el navegador del usuario. La cookie se llama"token"y almacena el JWT (token).httpOnly: true:Esto significa que el JavaScript que se ejecuta en el navegador no puede acceder a la cookie. Es una función de seguridad para evitar que scripts maliciosos roben el token.sameSite: "strict": Esto ayuda a proteger contra ataques CSRF (falsificación de solicitud entre sitios) . Garantiza que la cookie solo se envíe cuando el usuario interactúa directamente con su sitio (no cuando se lo engaña para que haga clic en un enlace de otro sitio).secure: process.env.NODE_ENV === "production":Esto garantiza que la cookie solo se envíe a través de conexiones HTTPS seguras en un entorno de producción. En el desarrollo, se puede enviar a través de HTTP para fines de prueba.maxAge: 7 * 60 * 60 * 1000:Esto establece el tiempo de expiración de la cookie en 7 días , al igual que el token.
¿Por qué es esto importante?
- La cookie es donde almacenamos el JWT para que el navegador pueda enviarlo automáticamente con cada petición. De esta forma, el servidor siempre sabe quién es el usuario sin que tenga que iniciar sesión nuevamente en cada carga de página.
Si omite este paso:
- Si no instala la cookie, el navegador no almacenará el token y el usuario deberá iniciar sesión nuevamente cada vez que actualice la página o visite una nueva página en su sitio. La sesión del usuario no se mantendrá y se cerrará la sesión constantemente.
El panorama más amplio: ¿Por qué utilizar JWT y cookies para la autenticación?
El uso de JWT y cookies para la autenticación tiene varias ventajas:
- Autenticación sin estado : los JWT permiten que el servidor permanezca sin estado . Esto significa que el servidor no necesita almacenar datos de sesión para cada usuario. En cambio, el JWT se envía con cada solicitud y el servidor puede verificarlo rápidamente.
- Seguridad : al utilizar una clave secreta para firmar el JWT, el servidor garantiza que el token no haya sido alterado. El almacenamiento del JWT en una cookie httpOnly agrega una capa adicional de seguridad, lo que evita que los scripts del lado del cliente accedan al token.
- Comodidad para el usuario : una vez que el usuario inicia sesión, no necesita volver a ingresar sus credenciales cada vez que carga una nueva página o vuelve a visitar el sitio dentro de los 7 días.
¿Qué sucede si omite la autenticación JWT?
Resumamos lo que sucederá si omite la generación del token o su configuración en una cookie:
- Sin token : si no genera un JWT, el servidor no sabrá quién es el usuario después de que inicie sesión. Como resultado, el usuario no podrá acceder a partes del sitio que requieren autenticación (como ver su perfil o realizar acciones como un usuario conectado).
- Sin cookies : aunque se genere el token, si no se almacena en una cookie, el navegador no lo recordará. El usuario perderá su estado de autenticación después de actualizar la página o visitar una nueva página, y se lo tratará como si hubiera cerrado la sesión.
Conclusión
En esta publicación, hemos explorado los conceptos básicos de los JWT y las cookies para la autenticación de usuarios en aplicaciones web. El código que analizamos le ayuda a:
- Generar un JWT que pruebe la identidad del usuario.
- Almacene este token en una cookie para que el navegador del usuario lo envíe automáticamente con cada solicitud.
Al utilizar JWT y cookies, puede administrar de manera eficiente y segura las sesiones de usuario, permitiéndoles permanecer conectados y acceder a áreas protegidas de su sitio.