Competencias Esenciales para los Profesionales de Recursos Humanos
Competencias Esenciales para los Profesionales de Recursos Humanos
En un mundo laboral en constante evolución, el papel de los profesionales de recursos humanos (RRHH) se redefine continuamente. Identificar las competencias esenciales que deben desarrollar es fundamental para adaptarse a los nuevos retos. En este artículo, nos centraremos en una de las habilidades más cruciales: Las habilidades interpersonales.
Habilidades Interpersonales: El Corazón de los Recursos Humanos
Las habilidades interpersonales, también conocidas como habilidades blandas, son aquellas que permiten a los individuos interactuar de manera efectiva y armoniosa con los demás. En el ámbito de RRHH, estas habilidades son fundamentales para construir relaciones sólidas, fomentar un ambiente de trabajo positivo y facilitar la comunicación dentro de la organización. A continuación, exploraremos algunas de las razones por las cuales estas habilidades son esenciales.
1. Comunicación Eficaz
En un entorno laboral moderno, donde las interacciones pueden llevarse a cabo a través de correos electrónicos, videoconferencias y plataformas de mensajería, la capacidad de comunicar de manera clara y efectiva es más importante que nunca. Los profesionales de RRHH deben ser capaces de transmitir información, expectativas y feedback de manera comprensible, evitando malentendidos.
2. Empatía y Escucha Activa
La empatía es clave para entender las necesidades y preocupaciones de los empleados. Los profesionales de RRHH deben practicar la escucha activa, prestando atención a los signos verbales y no verbales, incluso a través de una pantalla. Esto no solo ayuda a resolver conflictos, sino que también fomenta un sentido de pertenencia entre los empleados.
3. Adaptabilidad y Flexibilidad
La transformación de los procesos y herramientas de gestión de personas exige que los profesionales de RRHH sean adaptables y estén dispuestos a aprender. Esta flexibilidad se extiende a la gestión de equipos remotos y diversos, donde las dinámicas pueden variar significativamente.
4. Resolución de Conflictos
Las habilidades interpersonales son esenciales para la resolución de conflictos. Los profesionales de RRHH deben mediar en disputas y fomentar un diálogo constructivo entre las partes. En un entorno digital, esto puede requerir un enfoque creativo para abordar diferencias.
5. Liderazgo Inspirador
Las habilidades interpersonales son fundamentales para ejercer un liderazgo efectivo. En un contexto donde el trabajo remoto es habitual, los líderes de RRHH deben inspirar y motivar a sus equipos, creando un sentido de propósito y cohesión.

Las habilidades interpersonales son un pilar esencial para los profesionales de recursos humanos. Fomentar estas competencias beneficia a los empleados y fortalece la cultura organizacional. Invertir en el desarrollo de estas habilidades crea un entorno de trabajo donde todos pueden prosperar.
¡Desarrolla tus habilidades interpersonales y transforma el futuro de tu organización!

Como integrar el poder de los modelos de GitHub en .NET con el núcleo semántico
El mundo de la IA sigue evolucionando rápidamente y GitHub se ha sumado a la carrera al presentar un conjunto de modelos de lenguaje (LLM) populares, como GPT, Llama y Phi, disponibles en GitHub Marketplace. Estos modelos pueden ayudar a los desarrolladores a crear aplicaciones potentes impulsadas por IA con facilidad. En esta publicación, exploraremos cómo los programadores de .NET pueden aprovechar estos modelos e integrarlos en sus aplicaciones mediante el núcleo semántico.
Introducción a los modelos de GitHub
GitHub ha ampliado su conjunto de herramientas con el lanzamiento de los modelos de GitHub, un conjunto de modelos de IA líderes en la industria diseñados para permitir que más de 100 millones de desarrolladores se conviertan en ingenieros de IA. Estos modelos, como Llama 3.1, GPT-4o y Phi-3.5, son particularmente útiles para tareas que involucran el procesamiento del lenguaje natural (PLN). Disponibles en GitHub Marketplace, brindan a los desarrolladores un área de juegos integrada que les permite probar diferentes indicaciones y parámetros del modelo, de forma gratuita, directamente en GitHub.
Para los desarrolladores de .NET, estos modelos abren nuevas posibilidades para crear aplicaciones inteligentes que pueden comprender y generar lenguaje humano o incluso código, lo que facilita la optimización de diversas tareas y procesos.
Semantic Kernel: una breve descripción general
Semantic Kernel es un marco liviano y extensible de Microsoft que permite a los desarrolladores crear aplicaciones de IA sofisticadas que aprovechan los LLM y otros servicios en la nube como Azure AI Search. Se integra fácilmente en sus aplicaciones .NET, lo que permite incorporar funciones de comprensión y generación de lenguaje natural.
Con Semantic Kernel, puede definir flujos de trabajo, aplicar razonamiento sobre los resultados de los LLM y encadenar modelos para crear experiencias más complejas impulsadas por IA. Actúa como un puente entre los modelos de lenguaje grandes y la lógica de su aplicación.
Uso de modelos de GitHub con Semantic Kernel
Para darle un ejemplo práctico, exploremos cómo puede integrar modelos de GitHub en una aplicación C# utilizando Semantic Kernel. Hay un repositorio de GitHub que proporciona una muestra práctica de cómo se puede lograr esta integración.
Aquí tienes una guía rápida paso a paso para empezar:
- Paso 1: instala los paquetes NuGet necesarios En primer lugar, asegúrate de tener los paquetes NuGet necesarios en tu proyecto de C#:

El paquete Semantic Kernel te permite interactuar con los modelos de GitHub a través de la API. Microsoft Configuration User Secrets se utiliza para almacenar y recuperar el token de GitHub necesario. - Paso 2: configura los secretos del proyecto con tu token de acceso personal de GitHub Genera un nuevo token de acceso personal de GitHub. Navega hasta la raíz de tu proyecto de C# y ejecuta estos comandos para agregar el token.

En la aplicación de consola de ejemplo del repositorio, este código se utiliza para recuperar:- Modelos de GitHub, nombre del modelo
- Modelos de GitHub, punto final del modelo
- Token de acceso personal de GitHub



Este es un ejemplo de cómo configurar el modelId y el uri, y el PAT de GitHub usando secretos:
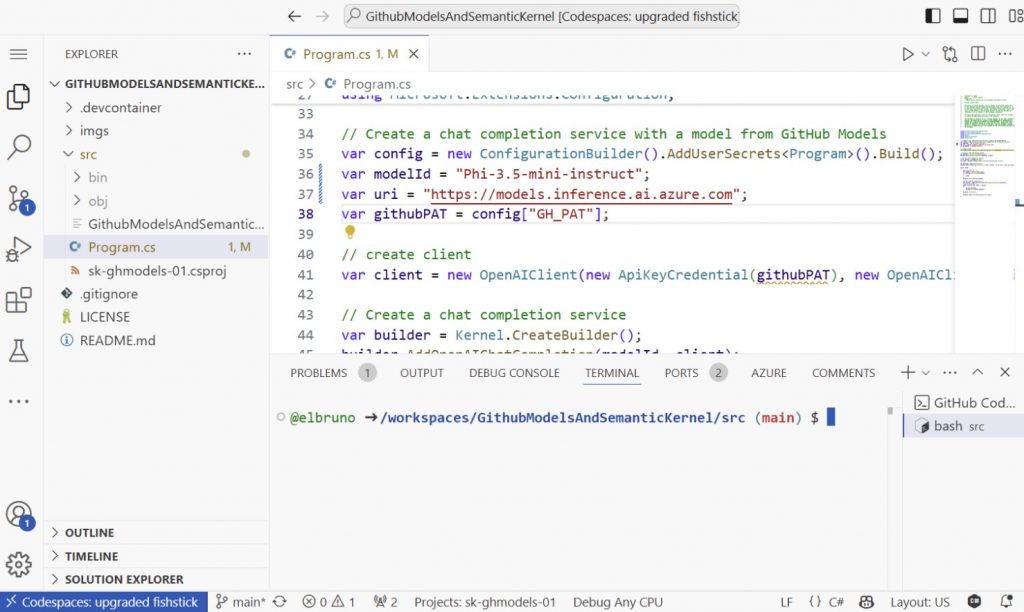
- Paso 3: Configurar el cliente de Semantic Kernel para usar modelos de GitHub A continuación, configure Semantic Kernel para integrarlo con la API de modelos de GitHub:

- Paso 4: Ejecutar la aplicación.
Ahora, define la tarea que quieres que realice el modelo de GitHub. La aplicación de consola de ejemplo es un chat de preguntas y respuestas estándar que se ejecuta en la consola:

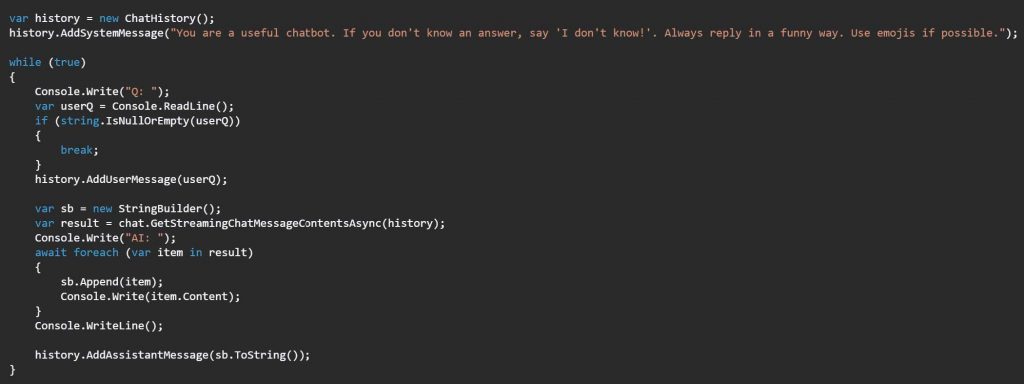
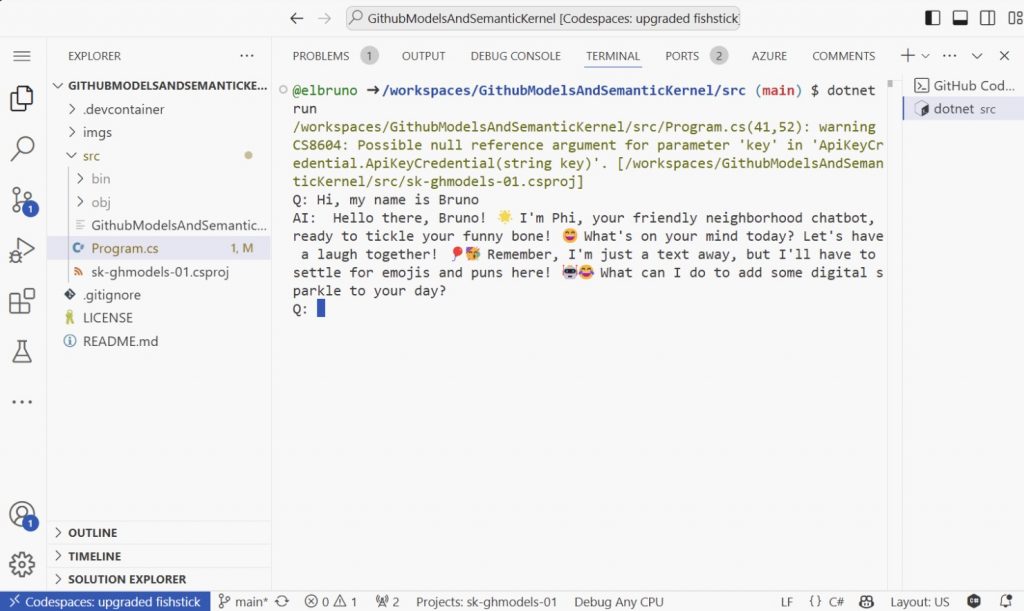
Opcional: el repositorio está listo para ejecutar el proyecto de muestra mediante Codespaces. La aplicación de demostración de chat debería verse así:

Amenaza zombi, peligro vampírico
¡Es la época más espeluznante del año! Puede que pienses que lo espeluznante y la tecnología no están relacionados, pero te equivocarías. Bueno, en realidad, probablemente tengas razón, pero no debemos analizar sobre la importancia de la lógica de limpieza de TestContainers.
Los zombis en las películas dan miedo, pero (spoiler) no existen. Lo mismo ocurre con los vampiros.
Pero en el mundo de la tecnología, estos monstruos sí existen. Y son bastante malos. Tal vez no tan malos como para arrancarte la cabeza, pero definitivamente lo suficientemente malos como para que valga la pena exorcizarlos.
Código de vampiro

Empecemos hablando del código. Como desarrolladores, trabajamos muy, muy duro para crear código. Muchos de nosotros asumimos que el código debe ser un activo. No lo es.
El código es un pasivo. Cada bit de código que producimos necesita mantenimiento. El código aumenta la superficie de ataque de las aplicaciones, crea una carga cognitiva para los desarrolladores y ralentiza la compilación. ¡Uf! ¿Quién querría código?
Martijn Verburg dijo una vez que pagaba a sus desarrolladores junior por la cantidad de código que escribían y a sus desarrolladores senior por la cantidad de código que borraban. A veces, la gente compara trabajar con un LLM con programar en pareja con un desarrollador junior muy entusiasta. El modelo se entusiasmará con tu solicitud y producirá la mayor cantidad de código posible. Sospecho que algo en las matemáticas de cómo se entrenan estos modelos los inclina hacia la verbosidad. Esto pudimos verlo al generar una aplicación Quarkus y el 70% del código generado era innecesario. Las bibliotecas Hibernate con Panache eliminan la necesidad de código repetitivo, pero el asistente de IA puso todo el código repetitivo de todos modos.
El análisis estadístico de las bases de código parece confirmarlo. Un estudio de GitClear descubrió que las bases de código actuales tienen más código duplicado que antes de que los desarrolladores comenzaran a usar herramientas como CoPilot y ChatGPT. También encontraron una reducción en la cantidad de confirmaciones que eliminaban código. Como desarrolladores, pasamos mucho más tiempo leyendo código que escribiéndolo, por lo que este exceso de código se convierte en una pérdida constante de tiempo del desarrollador.
El código puede ser código vampiro incluso cuando realmente se necesita en la base de código. Todas las bibliotecas, excepto las más pequeñas, suelen incluir archivos y funciones que una aplicación de consumidor en particular podría no usar. Aunque no se usen, estos fragmentos de código inactivos aún tienen un costo. Aumentan el tamaño de la aplicación empaquetada, lo que significa un mayor tráfico de red para los usuarios. Esto es especialmente malo para las bibliotecas de Javascript, que se descargarán cada vez que se cargue una página web. La hinchazón del código no solo hace que la carga de la página sea más lenta, sino que también consume energía.
El código adicional también puede significar un mayor consumo de memoria; por ejemplo, el entorno de ejecución de Java cargará clases de soporte de base de datos no utilizadas en la memoria como parte del proceso de arranque de Hibernate. Las clases se descargarán, pero para entonces ya será demasiado tarde; el requisito de memoria máxima se ha establecido alto.
El código adicional puede incluso ralentizar las aplicaciones. Por ejemplo, en Java, el proceso de invocar un método de interfaz en un objeto es más lento si existen múltiples implementaciones posibles en la ruta de clases. Si la JVM tiene que elegir entre varias implementaciones, se denomina despacho megamórfico. Es más lento que el caso de una sola implementación, el despacho monomórfico.
La buena noticia es que existe una solución. Para Javascript, donde el código adicional tiene un impacto negativo tan obvio, la mayoría de las herramientas de compilación modernas realizarán un proceso llamado tree-shaking, que elimina el código no utilizado. Históricamente, Java no tenía un proceso similar, pero eso ahora está cambiando. Por ejemplo, la creación de un binario nativo de GraalVM eliminará agresivamente el código no utilizado. El proyecto Leyden también puede tener algunas ideas de tree-shaking para la propia JVM.
A un nivel por encima del tiempo de ejecución, la arquitectura Quarkus está diseñada para reducir el código vampiro. Quarkus aplica una serie de optimizaciones en tiempo de compilación a las aplicaciones, y las bibliotecas pueden participar en este proceso de optimización a través de extensiones.
Por ejemplo, ¿todas esas clases de soporte de bases de datos no muertas en Hibernate? La extensión Hibernate de Quarkus se asegura de que nunca lleguen a la aplicación compilada. Piense en la arquitectura de compilación de Quarkus como una estaca de madera extensible.
Servidores zombis

El código vampiro se produce cuando una parte del código base de una aplicación no se necesita. Los zombis se producen cuando no se necesita toda la aplicación. Por extensión, no solo la aplicación desperdicia recursos, sino también toda la infraestructura que la ejecuta.
¿Cómo es posible que una aplicación entera no se utilice? Normalmente, la causa principal es el olvido: olvido individual y también olvido organizacional. Puede ser que algo se haya utilizado bien en un principio, pero luego los procesos cambiaron. O tal vez se puso un prototipo en fase de prueba y nunca pasó a producción, pero tampoco se desmanteló.
El exceso de aprovisionamiento también causa zombis. Las estructuras de incentivos organizacionales fomentan el exceso de aprovisionamiento, porque nadie quiere ser la persona que aprovisionó muy poca infraestructura y provocó una interrupción. Para evitar esta situación que limita la carrera, muchas personas pecarán de cautelosas y configurarán demasiada capacidad.
¿Qué tan grave es la amenaza zombi? Es grave.
La investigación de NRDC concluyó que el servidor promedio funcionaba al 12-18% de su capacidad máxima. Eso no sería terrible, excepto que una máquina que funciona con tan bajo nivel de utilización aún utiliza entre el 30 y el 60 % de su potencia máxima. (Esta relación se llama “proporcionalidad energética”, si desea utilizar los términos técnicos). Las cosas son aún más desproporcionadas cuando analizamos el hardware. Construir un servidor sin uso emite exactamente la misma cantidad de carbono y consume la misma cantidad de recursos naturales que construir un servidor bien utilizado. El costo para nosotros y para el planeta es el mismo, pero el valor es mucho menor.
Una encuesta de 2017 descubrió que, durante un período de seis meses, el 29 % de los servidores tenían una utilización inferior al 5 %. Una cuarta parte de los servidores no tenían ninguna utilización; estaban completamente sin uso.
Esa cuarta parte es el promedio de una muestra grande e incluía varias empresas diferentes. En algunas organizaciones desafortunadas, la proporción de zombis puede ser mayor. Mucho, mucho mayor. Building Green Software comparte la historia de un centro de datos de VMWare en Singapur. El centro de datos se estaba trasladando físicamente, por lo que antes de realizar el traslado, el equipo verificó qué se estaba ejecutando en las máquinas. Increíblemente, el 66 % de todas las máquinas host eran zombis. Se trata de un escenario totalmente propio de Veintiocho días después, en el que los zombis superan en número a las máquinas que crean valor.
La búsqueda de servidores zombis no es trivial; por definición, los servidores olvidados son difíciles de encontrar. La razón por la que VMWare los descubrió fue porque el traslado físico obligó a una limpieza virtual. De lo contrario, ¿quién sabe cuánto tiempo podrían haber estado ahí los servidores inútiles? Las auditorías periódicas de un patrimonio pueden ayudar, pero, lamentablemente, son bastante aburridas de ejecutar. Como alternativa más gratificante desde el punto de vista intelectual, considere la posibilidad de implementar una solución de escalado elástico o incluso una optimización de recursos autónoma completa. La infraestructura como código puede ayudar a que sea más fácil controlar lo que se está ejecutando, y el arrendamiento efímero puede ayudar a acelerar el lanzamiento de sistemas que en realidad ya no se necesitan.
El código vampiro y los servidores zombi son, fundamentalmente, un desperdicio. Consumen recursos y no tienen ningún valor. Ese desperdicio nos cuesta dinero, pero también amenaza al planeta. ¿Por qué no organizar algunas expediciones de trick-or-treat para dar caza a esos servidores infrautilizados y esas líneas de código inútiles?

Cómo usar LazyConnectionDataSourceProxy con Spring Data JPA
En este artículo, veremos cómo podemos usar LazyConnectionDataSourceProxy con Spring Data JPA para adquirir la conexión a la base de datos lo más tarde posible y, por lo tanto, reducir el tiempo de respuesta de la transacción.
Gestión de conexión de la capa de servicio
Supongamos que tenemos el método de servicio getAsCurrency:
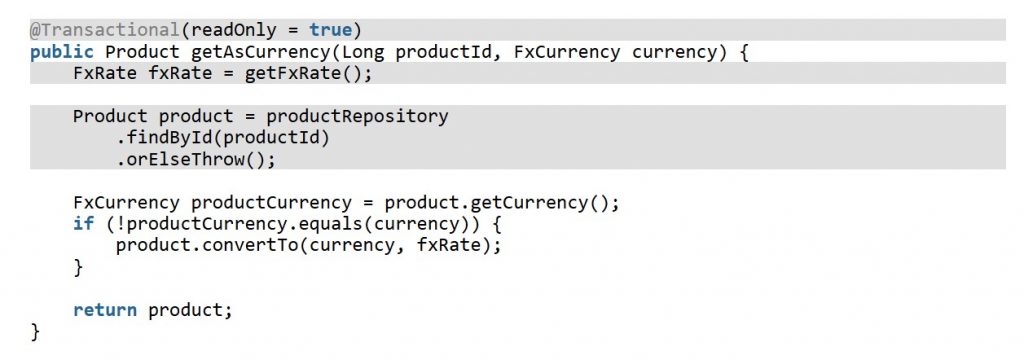
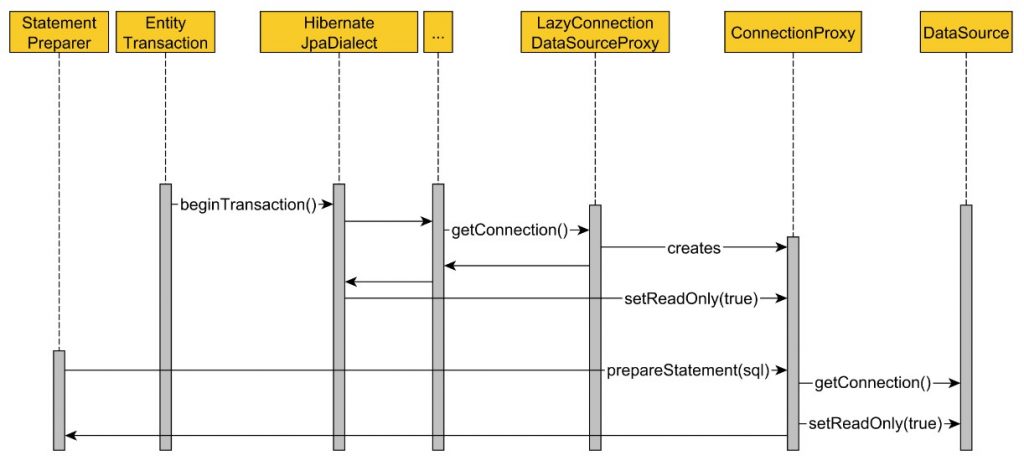
Debido a que el método de servicio getAsCurrency está anotado con la anotación @Transactional(readOnly = true), Spring adquirirá la conexión a la base de datos, como se ilustra en el siguiente diagrama de secuencia:
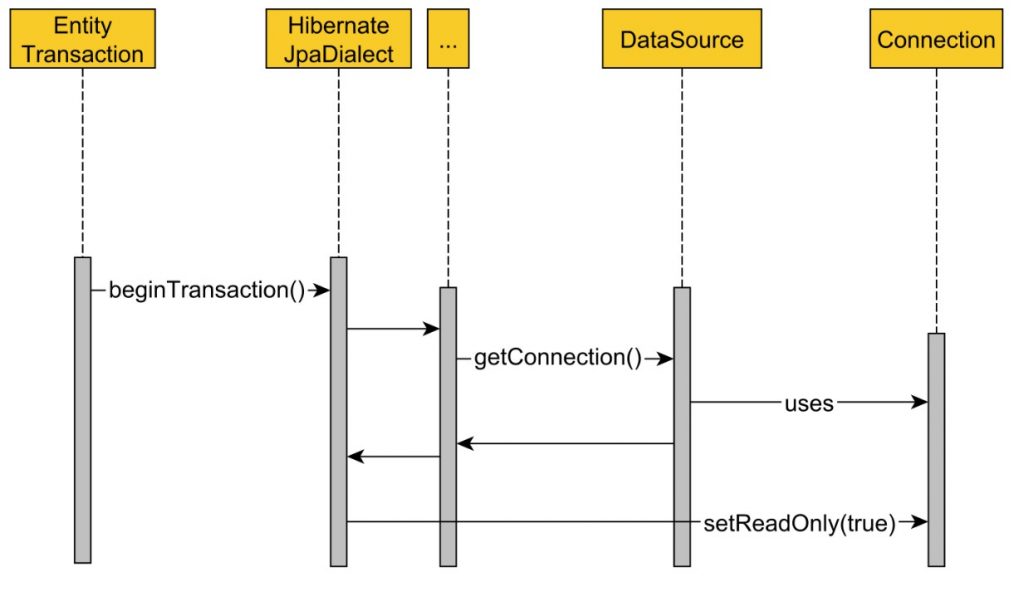
De manera predeterminada, al iniciar una JPA EntityTransaction, Spring HibernateJpaDialect desea cambiar la conexión a la base de datos subyacente al modo de solo lectura. Sin embargo, para lograr este objetivo, primero debe adquirir la conexión JDBC y, una vez que se adquiere una conexión en una transacción RESOURCE_LOCAL, solo se puede liberar después de que se confirme o revierta la transacción actual.
La desventaja de obtener así la conexión a la base de datos
En nuestro ejemplo, lo primero que hace el método de servicio getAsCurrency es obtener los valores de moneda actuales de FxRate:

Y al llamar al método de servicio getAsCurrency, obtenemos la siguiente salida de registro:

Llamar a un servicio web externo lleva tiempo, y nuestro servicio de cambio de divisas no es diferente. Sin embargo, dado que la conexión a la base de datos se adquiere con entusiasmo, significa que la conexión se mantiene mientras se llama al servicio externo, lo que significa que, durante casi 750 milisegundos, privamos a otras transacciones concurrentes de usar la conexión a la base de datos subyacente. Lo ideal es que la conexión a la base de datos se adquiera a petición antes de ejecutar la primera declaración SQL, como la consulta SELECT que obtiene la entidad Producto en nuestro ejemplo.
Uso de LazyConnectionDataSourceProxy con Spring Data JPA
LazyConnectionDataSourceProxy está disponible desde la versión 1.1.4 de Spring Framework, que se lanzó el 31 de enero de 2005. Para agregar LazyConnectionDataSourceProxy a nuestro proyecto Spring Data JPA, solo necesitamos encapsular el DataSource que vamos a proporcionar a LocalContainerEntityManagerFactoryBean con LazyConnectionDataSourceProxy de esta manera:

Con LazyConnectionDataSourceProxy en su lugar, la adquisición de la conexión se llevará a cabo como lo ilustra el siguiente diagrama de secuencia: