
Meta pisa el acelerador en la carrera de la inteligencia artificial
A principios de febrero, coincidiendo con la presentación de sus resultados trimestrales, Marck Zuckerberg lanzaba un aviso a navegantes, casi, casi una declaración de intenciones: Meta quiere ser «líder en Inteligencia Artificial (IA) generativa». En un sector marcado por la competencia, con OpenAI, Microsoft o Google apostando fuerte, la antigua Facebook quiere demostrar que no piensa solo en el metaverso y hacerse notar en un campo que, en realidad, lleva explorando desde que en 2013 puso en marcha el grupo Facebook AI Research (FAI).
Ayer la compañía y el propio Zuckerberg quisieron ir más allá y reivindicar su presencia en la carrera de la IA presentando su nuevo modelo: LLaMA.
¿Qué es eso de LLaMA? Las siglas de Large Language Model Meta AI, un modelo de lenguaje que la compañía ha decidido enfocar a los investigadores en el campo, precisamente, de la inteligencia artificial. El matiz es importante. LLaMA se plantea a modo de herramienta para investigadores, no como un sistema con el que cualquiera pueda interactuar, caso de ChatGPT o el nuevo bot de Bing. Meta ha decidido lanzarlo en varios tamaños—65B, 33B, 13B y 7B—, entrenados con diferentes cantidades de tokens y textos en una veintena de idiomas distintos.
«LLaMA-13B supera a GPT-3 (175B) en la mayoría de las pruebas, y LLaMA-65B compite con los mejores modelos, Chinchilla70B y PaLM-540B», asegura Meta, que reconoce, eso sí, que «la tasa de respuestas correctas sigue siendo baja».
¿Y cuál es el objetivo del modelo? Mark Zuckerberg aseguraba ayer que su propósito es «ayudar a los investigadores a avanzar en su trabajo» en el campo de la IA. «Los modelos más pequeños y de mayor rendimiento como LLaMA permiten estudiarlos a otros miembros de la comunidad investigadora sin acceso a grandes infraestructuras, lo que democratiza todavía más el acceso a este campo tan importante y cambiante», reivindica la multinacional en su blog oficial.
Meta asegura que LlaMA requiere «mucha menos potencia y recursos informáticos» a la hora de experimentar con nuevos enfoques, validar trabajos y explorar aplicaciones. “A pesar de los recientes avances en los modelos lingüísticos de gran tamaño, la investigación sigue teniendo un acceso limitado a ellos debido a los recursos necesarios para entrenarlos y ejecutarlos”, subraya.
¿Trabajar en qué? Meta reconoce que los modelos lingüísticos han avanzado en la generación de textos, la resolución de problemas matemáticos o la respuesta de preguntas de comprensión lectora, pero asegura que las restricciones de acceso que ocasionan los recursos necesarios para su entrenamiento ha limitado la capacidad de los investigadores para comprender cómo funcionan: «Han obstaculizado los avances en los esfuerzos por mejorar su solidad y mitigar problemas conocidos, como el sesgo, la toxicidad y el potencial para generar información errónea».
«Aún queda mucho por investigar para hacer frente a los riesgos de sesgo, comentarios tóxicos y alucinaciones en los grandes modelos lingüísticos. Al igual que otros modelos, LLaMA comparte estos retos […]. Al compartir el código otros investigadores pueden probar más fácilmente nuevos enfoques para limitar o eliminar estos problemas en grandes modelos», recalca la antigua Facebook.
¿Es accesible LLaMA? Meta ha publicado su modelo bajo una licencia no comercial centrada en su uso para investigaciones. El acceso, detalla, se concederá “caso por caso” a investigadores académicos que estén afiliados a organismos y laboratorios. Quienes quieran solicitarlo deben enviar una solicitud. ¿El motivo? La compañía quiere «mantener su integridad y evitar usos indebidos».
¿Es importante el contexto? Desde luego. El anuncio de Meta llega poco después de que el propio Zuckerberg reivindicase que aspira a ser «líder en AI generativa» y en plena carrera por el desarrollo de herramientas. A lo largo de los últimos meses Microsoft ha apostado con contundencia por OpenAI y aprovechado el potencial de ChatGPT para dar un impulso a Bing. Mientras, Google presentaba su propia IA conversacional (Bard) y herramientas como MusicLM.
¿Es este el primer movimiento de Meta? No. En noviembre su área de investigación de IA, capitaneada por Yann LeCun, ya lanzó una herramienta de IA orientada a los investigadores y basada también en Large Language Model, LLM: Galactica. «Puede resumir literatura académica, resolver problemas matemáticos, generar artículos Wiki o escribir código científico», aseguraban sus responsables coincidiendo con el lanzamiento de una demo que permitía probarla.
El experimento no salió sin embargo cómo esperaba. Poco después la multinacional se veía obligada a recular y echar el freno a la demostración entre críticas de científicos que aseguraban que en ocasiones las respuestas de Galactica no eran correctas. «Le pregunté sobre cosas que sé y estoy preocupado. En todos los casos estaba mal o sesgado, pero sonaba correcto y con autoridad. Creo que es peligroso», alertaba Michael Black, del Instituto Max Planck. También el nuevo Bing se ha visto en la necesidad hace poco de ajustarse sobre la marcha.
Fuente: Xataka

Clean Code: ¿Qué es y por dónde empezar?
En este artículo vamos a describir la filosofía del Clean Code o Código Limpio, indicando los principios en los que se basa, y a mostrar las múltiples ventajas que tiene su uso y mostraremos ejemplos de código en los que se utilizan estas técnicas.
¿Qué es?
Clean Code es una filosofía utilizada en el desarrollo de software cuyo objetivo es hacer más fácil la lectura y escritura de código. Se basa en la aplicación de técnicas sencillas con las que generamos un código claro e intuitivo que es más fácil de modificar. Es especialmente útil cuando se trabaja en grupo, ya que es posible que tu código lo tenga que modificar posteriormente otra persona.
Escribir código limpio puede implicar tanto escribir más código de lo normal como escribir menos, dependerá de las circunstancias, pero siempre dejará claro lo que quiere conseguir. Las técnicas mencionadas anteriormente se basan en gran medida en el contenido del libro escrito en 2008 por Robert C. Martin y titulado “Clean Code: A Handbook of Agile Software Craftsmanship”. En este libro, se habla acerca de cómo generar código que al estar bien estructurado sea fácil de entender y, por tanto, sea fácil de mantener. Es un libro útil para cualquier desarrollador, independientemente de la experiencia que tenga. Si eres un desarrollador con experiencia seguro que hay detalles que no tenías en cuenta y que puedes poner en práctica para mejorar. Sin duda resultará mucho más útil para desarrolladores de software principiantes porque les proporcionará una buena base para generar un código de calidad.
Principios generales
A continuación, voy a describir las principales reglas en las que se basa el Clean Code:
Nombres descriptivos
La idea de este principio es que las variables, funciones, clases, métodos, etc… tienen que tener un nombre que exprese su intención. Es decir, solo con leer el nombre de un objeto deberíamos saber cuál es su propósito. Puede parecer algo insignificante, pero es muy importante para entender el código. Un ejemplo muy sencillo, pero con el que se entiende bien el concepto es el siguiente: si vamos a declarar una variable para almacenar el campo ZLSCH (vía de pago) de la tabla BSID, no lo llamemos lv_zlsch sino lv_viaPago.
Si, por ejemplo, una función necesita tener un nombre largo para que se entienda su función, adelante con ese nombre. No hay problema porque un objeto tenga un nombre largo, porque así evitaremos tener que adentrarnos en la función para saber qué es lo que hace. Para la nomenclatura de los objetos, podemos usar la práctica de escritura CamelCase. Consiste en unir dos o más palabras sin dejar espacios entre ellas y diferenciándolas en que la primera letra de cada palabra la ponemos en mayúscula (excepto la primera).
Regla del boy scout
Este principio es muy simple y consiste, aplicándolo a la codificación, en dejar el código que modifiques más limpio que como lo encontraste. Es decir, si modificas un código y ves cosas que no cumplen con el Clean Code, cámbialas para mejorar la calidad del código (aunque no formen parte de tu modificación).
Principio Don’t Repeat Yourself (DRY)
La traducción exacta de este principio sería “No te repitas a ti mismo”. Aplicado al área de la programación, consistiría en un mismo código que se repite en más de un sitio. Es habitual, pero es muy desaconsejable porque empeora la mantenibilidad del código. Además, es más probable que a causa de lo anterior, se produzcan errores, ya que se nos puede olvidar realizar un cambio en todos los sitios en donde esta ese código.
Solución para ello: crear una función que realice ese código y llamarla en todos los puntos donde sea necesario. De esta manera, si posteriormente hay que realizar un cambio solo habrá que hacerlo en un sitio, en la función.
Funciones
Una regla fundamental es que una función realice una sola cosa, y como hemos dicho anteriormente, el nombre de dicha función tiene que indicar cuál es esa cosa. Con ello generamos que cualquier programador pueda saber lo que realiza la función sin tener que mirar su código.
Tiene que ser lo más pequeña posible. Si una función es más grande de lo que debería, lo ideal es generar funciones que hagan distintas partes de ese código. Gracias a ello conseguimos que el código sea más reutilizable.
También es aconsejable usar el menor número posible de argumentos de entrada/salida, facilitando así entender lo que hace una función y también provocará que el tiempo usado para probarla sea menor porque las combinaciones posibles también son menores.
Otro consejo es utilizar siempre excepciones en vez de devolver códigos de error, porque con ellas queda más claro la causa del error sin tener que añadir más código o comentarios.
Estructura del código
Estructurar de manera clara el código provoca que sea más fácil de leer y por tanto de mantener. A continuación, os mostramos ideas de como estructurar el código:
- Nuestras diferentes variables deben declararse todas juntas al principio de la función, método, etc…
- Cada sentencia del código debe ir en una línea.
- Por lo tanto, las sentencias relacionadas deben estar en líneas consecutivas para separarlas del resto de código.
- Cada grupo de sentencias relacionadas deben separarse por líneas en blanco.
- Aunque no haya establecido un límite máximo de caracteres por línea, no es aconsejable escribir líneas de código muy largas porque dificulta la lectura rápida del código.
- Es importante tabular el código correctamente.
Todas estas ideas tan simples pueden mejorar mucho la lectura del código porque ahorramos tiempo a la hora de modificarlo. A la hora de trabajar en un equipo es muy aconsejable que todos sus miembros sigan estas directrices para no perder tiempo a la hora de extender el código.
No penalizar el rendimiento
Cuando se modifica un objeto existente, es importante no hacerlo de manera incorrecta y por tanto penalizando el rendimiento de ese programa, función, método, etc… Para ello, hay que revisar el objeto para ver el mejor sitio posible donde hacer la modificación. A pesar de que eso conlleve algo más de tiempo, es beneficioso a la larga porque nos ahorramos posteriormente tener que revisar el rendimiento de dicho objeto. Después de haber seguido todos los principios del código limpio, revisar ese objeto no nos llevará tanto tiempo como podríamos pensar.
Ventajas de usar Clean Code
Son múltiples las ventajas de usar estas técnicas. A continuación, comentamos algunas de ellas:
- El código es más fácil de leer para cualquier persona, sobre todo para aquella que no es quien lo ha desarrollo, es muy útil cuando se trabaja en equipo.
- El código es más fácil de mejorar y por tanto de mantener.
- Una situación bastante común es, debido a no entender bien el código ya desarrollado, implementar un nuevo cambio añadiendo código al final del objeto. Esto se evita utilizando estas técnicas, ya que el tiempo empleado en ver el punto a tocar es menor si se usan estas técnicas. De esta manera, añadimos el nuevo
código en el punto correcto y en poco tiempo. - La calidad del código aumenta considerablemente y, por tanto, la calidad de nuestro trabajo.
- Usando estas técnicas, se benefician no solo los demás, sino también nosotros mismos. Piensa que puedes ser tú mismo quien tenga que modificar un objeto (por ejemplo) un año después de la última modificación. ¿Crees que te acordaras de porque escribiste esas líneas de código? De esta manera, solo tendrás que leer el código para entenderlo y podrás realizar las modificaciones sin ningún problema.ç
- En definitiva, una ventaja esencial es que con estas prácticas generamos código limpio para todo el mundo.
Ejemplos prácticos de Clean Code
Ahora vamos a exponer ejemplos de cada una de las principales reglas del Clean Code:
Nombres descriptivos
En caso de tener que recuperar el campo BUKRS de la tabla de base de datos EVER para posteriormente mostrarlo en un ALV. Nombraremos esa variable con un nombre que nos permita saber que almacena sin tener que ir a ver la descripción de ese campo en la tabla de BBDD. Por tanto, en vez de generar un código como este:
DATA: lv_bukrs TYPE ever-bukrs.
SELECT SINGLE bukrs INTO lv_bukrs
FROM bukrs
WHERE vertrag EQ pi_contrato.
Debemos generar el siguiente:
DATA: lv_sociedad TYPE ever-bukrs.
SELECT SINGLE bukrs INTO lv_sociedad
FROM bukrs
WHERE vertrag EQ pi_contrato.
Otro ejemplo lo podríamos poner para los nombres de las funciones. Al generar una función para obtener el número de orden a partir del número de objeto, tenemos que ponerle un nombre que nos permita saberlo sin tener que entrar a mirar su código. Por tanto, en vez de ponerle el nombre (por ejemplo) “ZGet_aufnr”, deberíamos nombrarla “ZGet_Aufnr_From_Objnr”.
Regla del boy scout
Como ejemplo podría poner el siguiente: tenemos que añadir en un form de un programa una lógica para separar en 2 campos el valor de un campo y su descripción (actualmente se están mostrando concatenados en un solo campo). Y resulta que está obteniendo las descripciones del campo en una tabla interna normal.
¿Te limitarías a realizar tu cambio o mirarías si esta tabla se podría hacer por ejemplo hashed (tabla que es más rápida y por tanto mejora el rendimiento)? En eso consiste esta práctica. Tardarías algo más en hacer el cambio, ¡pero generaras un código de más calidad y más óptimo!
Principio Don’t Repeat Yourself
Hace muy poco tiempo en el trabajo usé este principio. Me pidieron modificar dos funciones para añadir en ambas un cambio consistente en cambiar la unidad de servicio en la operación de Servicios a certificar. La opción más rápida sería haber cambiado ambas funciones añadiendo las llamadas a las BAPI correspondientes. Sin embargo, de esa manera no hubiera cumplido este principio. Lo que hice fue generar una función Z en donde añadí las llamadas a las BAPI y, posteriormente, en ambas funciones llamé a la nueva función creada.
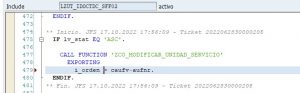
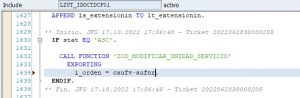
Me llevó algo más de tiempo codificarlo, pero posteriormente gané tiempo porque en las pruebas al tener que realizar cambios, solo tuve que realizarlos en un sitio. Además, de esta manera evité el problema de olvidarme de realizar los cambios en alguna de las dos funciones.
Funciones
Un ejemplo podría ser una función que realice ciertos cálculos aritméticos a partir de campos de una tabla de BBDD y que posteriormente actualice un registro de esa tabla. En vez de generar una sola función que haga ambas tareas, lo ideal en este caso, es generar una función para la actualización del registro y otra función que realice los cálculos aritméticos. Vamos a verlo en código.
FUNCTION ZGET_MODIFY_DUE_DATE.
CLEAR: lv_fecha_base_vencimiento,
lv_dias_descuento.
SELECT zfbdt zbd1t INTO (lv_fecha_base_vencimiento, lv_dias_descuento)
FROM bsik
UP TO 1 ROWS
WHERE lifnr EQ i_proveedor.
ENDSELECT.
CLEAR lv_fecha_vencimiento.
lv_fecha_vencimiento = lv_fecha_base_vencimiento + lv_dias_descuento.
CLEAR ls_info_proveedor.
SELECT SINGLE * INTO ls_info_proveedor
FROM zinfo_proveedor
WHERE lifnr EQ i_proveedor.
IF sy-subrc EQ 0.
ls_info_proveedor-zfecha_vencimiento = lv_fecha_vencimiento.
UPDATE zinfo_proveedor FROM ls_info_proveedor.
IF sy-subrc EQ 0.
CALL FUNCTION 'BAPI_TRANSACTION_COMMIT'
EXPORTING
wait = 'X'.
ENDIF.
ENDIF.
ENDFUNCTION.
En vez de crear una sola función con todo ese código, lo ideal es crear dos funciones que hagan cada una de las partes.
FUNCTION ZGET_DUE_DATE.
CLEAR: lv_fecha_base_vencimiento,
lv_dias_descuento.
SELECT zfbdt zbd1t INTO (lv_fecha_base_vencimiento, lv_dias_descuento)
FROM bsik
UP TO 1 ROWS
WHERE lifnr EQ i_proveedor.
ENDSELECT.
CLEAR e_fecha_vencimiento.
e_fecha_vencimiento = lv_fecha_base_vencimiento + lv_dias_descuento.
ENDFUNCTION.
FUNCTION ZMODIFY_DUE_DATE.
CLEAR ls_info_proveedor.
SELECT SINGLE * INTO ls_info_proveedor
FROM zinfo_proveedor
WHERE lifnr EQ i_proveedor.
IF sy-subrc EQ 0.
ls_info_proveedor-zfecha_vencimiento = i_fecha_vencimiento.
UPDATE zinfo_proveedor FROM ls_info_proveedor.
IF sy-subrc EQ 0.
CALL FUNCTION 'BAPI_TRANSACTION_COMMIT'
EXPORTING
wait = 'X'.
ENDIF.
ENDIF.
ENDFUNCTION.
Estructura del código
¿Entiendes mejor este código?
IF x_obj-trig-etrg-abrvorg2 EQ '03'.
DATA: lv_status_contrato TYPE ever-bstatus.
CLEAR lv_status_contrato.
SELECT bstatus INTO lv_status_contrato FROM ever UP TO 1 ROWS WHERE vertrag EQ i_ve
IF ( lv_status_contrato EQ '08' OR lv_status_contrato EQ '09' ).
DATA: lv_status_orden_calculo TYPE etrg-trigstat.
CLEAR lv_status_orden_calculo.
SELECT trigstat INTO lv_status_orden_calculo FROM etrg UP TO 1 ROWS WHERE anlage EQ
IF lv_status_orden_calculo EQ '01'.
DATA: lv_mensaje TYPE string.
* No permito la generación del cálculo
CLEAR lv_mensaje_error.
lv_mensaje_error = 'Cálculo de baja a la espera por lectura de ciclo anterior.'.
MESSAGE lv_mensaje_error TYPE 'I'.
RAISE general_fault.
ENDIF.
ENDIF.
ENDIF.
¿O este otro?
DATA: lv_status_contrato TYPE ever-bstatus,
lv_status_orden_calculo TYPE etrg-trigstat,
lv_mensaje TYPE string.
IF x_obj-trig-etrg-abrvorg2 EQ '03'.
8/9
CLEAR lv_status_contrato.
SELECT bstatus INTO lv_status_contrato
FROM ever
UP TO 1 ROWS
WHERE vertrag EQ x_obj-bill-erch-vertrag.
ENDSELECT.
IF ( lv_status_contrato EQ '08' OR lv_status_contrato EQ '09' ).
CLEAR lv_status_orden_calculo.
SELECT trigstat INTO lv_status_orden_calculo
FROM etrg
UP TO 1 ROWS
WHERE anlage EQ x_obj-trig-etrg-anlage AND
abrdats EQ x_obj-pbill-erch-abrdats.
ENDSELECT.
IF lv_status_orden_calculo EQ ’01’.
* No permito la generación del cálculo
CLEAR lv_mensaje_error.
lv_mensaje_error = 'Cálculo de baja a la espera por lectura de ciclo anterior.'.
MESSAGE lv_mensaje_error TYPE 'I'.
RAISE general_fault.
ENDIF.
ENDIF.
ENDIF.
Pues creo que aquí no hay mucho que decir. El segundo código se lee y se entiende mucho más rápido que el primero.
No penalizar el rendimiento
Para mostrar esta práctica se podría poner como ejemplo un cambio a realizar en un programa para mostrar el campo nuevo INVOICING_PARTY de la tabla de BBDD EVER en el ALV de salida que ya genera dicho programa.
Puede que ese programa sea muy extenso y que realice muchos select para la obtención de datos. Y puede que, para no perder tanto tiempo, no revisemos todos esos select y se nos escape que el programa ya busca en esa tabla de BBDD. Añadiríamos otro select a la misma tabla para obtener el nuevo campo. El cambio correcto sería modificar la consulta actual para recuperar también el campo nuevo.
En caso de elegir la opción incorrecta, podemos penalizar mucho el rendimiento. Debido a que no sería solo la nueva consulta a base de datos, sino también una nueva tabla interna para guardar los datos con su consecuente READ TABLE nuevo… Es decir, duplicaríamos muchas sentencias innecesarias. Contamos con una tabla grande puede que aumente considerablemente el tiempo de ejecución y por tanto las quejas de los usuarios. Usando las normas del Clean Code en este programa no se tardaría tanto en entender…
Con todo lo expuesto, podemos concluir que seguir estas prácticas de fácil aplicación mejoran la calidad del código, además de ahorrarnos tiempo al facilitarnos la lectura y por tanto el mantenimiento del código. Estas prácticas son útiles independientemente de la experiencia del programador y permiten que pueda extender el código cualquier persona, aunque no sea el autor.
Fuente: Viewnext

Las principales tendencias tecnológicas que tendrán un gran impacto en el año 2023
Las principales tendencias tecnológicas
Durante el año 2022, hemos sido testigos de transformaciones significativas en el campo de la Inteligencia Artificial.
No obstante, estas evoluciones marcan únicamente el inicio hacia la concreción de máquinas con capacidad creativa y el despliegue comercial de los ordenadores cuánticos.
¿QUÉ DEPARA EL FUTURO EN EL AÑO 2023?
La gestión del talento empresarial
Maquinas creativas
Las máquinas creativas están en auge gracias a la implementación de la inteligencia artificial generativa en los sistemas operativos convencionales.
Ya se han desarrollado herramientas como Dall-E 2 y ChatGPT, ambas creadas por OpenAI, que permiten la generación de imágenes y texto respectivamente.
Además, existe un modelo generativo para la música llamado Jukebox que imita el estilo de diferentes artistas para crear automáticamente nuevas canciones. También se utiliza la IA para subtitular en vivo tanto audio como video.
Estos generadores de contenido han evolucionado hasta tal punto que resulta cada vez más difícil diferenciar entre las obras creadas por IA y las creadas por humanos.
Desde hace tiempo, ha habido una gran inquietud por el impacto que la automatización pueda tener en el mercado laboral.
Las aplicaciones de IA más avanzadas de hoy en día no son capaces de igualar a los seres humanos en tareas creativas, como la conceptualización. Por tanto, la forma más inteligente de incorporar nuevas herramientas de IA es utilizarlas como un complemento para los trabajadores, en lugar de competir o reemplazarlos.

La realidad aumentada (XR)
Las tecnologías de realidad aumentada y virtual están transformando la XR de una tecnología experimental a una herramienta empresarial clave que puede impulsar nuevos modelos de negocio.
Además, están surgiendo nuevas posibilidades en cuanto a la expansión sensorial, donde ya se están desarrollando paquetes de estimulación olfativa y guantes hápticos para estimular el sentido del tacto.
También se está avanzando en la simplificación de las interacciones del usuario con la tecnología a través de interfaces cerebro-computadora no invasivas, que permitirán a los usuarios controlar avatares digitales y entornos mediante las ondas cerebrales.
Finalmente, las herramientas de realidad aumentada y sensores de movimiento permiten la interacción espacial con los datos físicos, sin la necesidad de crear un gemelo digital.

Metacloud
La estrategia conocida como Metacloud implica la generación de una capa de abstracción que permite el acceso a servicios comunes tales como almacenamiento, computación, IA, bases de datos, seguridad, operaciones, gobierno y desarrollo e implementación de aplicaciones.
Esta capa de abstracción se ubica por encima de las distintas plataformas de nube de una compañía y utiliza las API originales de los proveedores de referencia en la nube para asegurar un funcionamiento coherente y control centralizado.
Metacloud lo lleva a cabo a través de una interfaz universal, permitiendo a los encargados tener un control centralizado sobre las múltiples instancias en la nube. En términos comparativos, Metacloud funciona como un sistema operativo de ordenador, gestionando los recursos en la nube y exponiendo las API a las aplicaciones.

Logística autónoma
Los altos ejecutivos de las empresas más importantes continuarán impulsando la implementación de sistemas autónomos, especialmente en lo que se refiere a la entrega y la logística. Cada vez son más las fábricas y los centros de distribución que están migrando hacia modelos parcial o completamente autónomos.
Para el año 2023, se prevé una mayor presencia de vehículos de reparto, camiones y barcos autónomos, robots de entrega, así como más almacenes y fábricas con tecnología autónoma. Además, los responsables de tecnología de la información de estas compañías tienen la tarea de mejorar el rendimiento de estas tecnologías al servicio del negocio.
Entre las últimas tecnologías y herramientas que las empresas pueden adoptar para aumentar la eficiencia y optimizar los procesos productivos se encuentran los RPA (Robotic Process Automation), que permiten automatizar tareas y procesos repetitivos mediante algoritmos informáticos.
Esto no solo significa un ahorro significativo de costos, sino que también mejora la calidad del servicio al reducir los errores humanos en la ejecución de tareas repetitivas.

Computación cuántica
La computación cuántica utiliza las propiedades cuánticas de las partículas subatómicas para crear nuevas formas de procesamiento y almacenamiento de información.
Esta revolución tecnológica tiene el potencial de proporcionar ordenadores capaces de operar millones de veces más rápido que los actuales. Se espera que durante el 2023, las empresas dedicadas a la computación cuántica realicen avances significativos en relación con esta tecnología.
Sin embargo, es importante tener en cuenta que la computación cuántica puede presentar un riesgo para la privacidad y la seguridad de la información, ya que puede hacer poco efectivas las prácticas de cifrado actuales.
Si una nación desarrolla la tecnología de la computación cuántica a gran escala, tendría la capacidad teórica de romper el cifrado de otros gobiernos, empresas y sistemas de seguridad. Este tema será crucial durante el 2023, especialmente a medida que países como Estados Unidos, Reino Unido y China continúen avanzando en la investigación y desarrollo de la tecnología de la computación cuántica.

Departamento de Comunicación Grupo Hasten
Las principales tendencias tecnológicas
Las principales tendencias tecnológicas
Las principales tendencias tecnológicas

La gestión del talento empresarial
La gestión del talento empresarial
La eficacia de cualquier empresa está estrechamente relacionada con su personal, es decir, las habilidades de las personas que la componen. Son ellos los que impulsan la funcionalidad de los procesos productivos, ya sea para la fabricación de bienes o para ofrecer servicios.
La gestión del talento empresarial
En la actualidad, se considera a los empleados como un recurso valioso para la organización, ya que su conjunto de habilidades, conocimientos y destrezas son esenciales para el éxito de la empresa.
Sin embargo, el rendimiento del personal está influenciado por varios factores que pueden afectar positiva o negativamente el desempeño y la competitividad de la empresa. Por esta razón, la gestión del talento se ha vuelto cada vez más importante en las organizaciones como una estrategia para aprovechar el potencial de las personas.
Se trata de ver a los empleados de una empresa como individuos con habilidades y capacidades, visibles o ocultas, que aportan un valor inestimable e inagotable en comparación con los recursos materiales que también son parte de los procesos productivos.
En resumen, la gestión de talentos humanos mejora el desempeño laboral en términos de eficiencia, eficacia, calidad y cantidad, lo que se traduce en un aumento en la rentabilidad de la empresa.
Para lograrlo es esencial conocer los fundamentos de la gestión de talentos y cómo implementarlo en una empresa.
Es esencial equilibrar los aspectos financieros, los activos materiales y el personal dentro de una empresa, ya que cada uno contribuye al éxito del negocio.
La atención al talento es crucial para el progreso y la transformación de la compañía, ya que los empleados son quienes impulsan y llevan a cabo el proyecto.
Dedicar atención y esfuerzo por parte del área de recursos humanos para comprender a los trabajadores de la empresa es fundamental. Esto te permitirá identificar problemas y mejorar, así como entender cómo es percibida tu empresa por los demás.
Aunque puede parecer una tarea difícil y que requiere mucho tiempo, en realidad, desarrollar una buena estrategia de employer branding tiene muchos beneficios para las empresas que la llevan a cabo de manera efectiva.
Estos beneficios incluyen un aumento en la productividad de la empresa, una mayor promoción de la innovación, una alta rentabilidad de la inversión en capital humano, un crecimiento tanto del negocio como de los empleados, mayor calidad en el trabajo, mayor competitividad, una triple satisfacción (empresarial, personal y del cliente) y una mayor fidelización de los empleados.
El primer paso para alcanzar estos beneficios es a través de una buena estrategia de employer branding, pero una vez que se cuenta con buenos profesionales en el equipo, es importante saber valorarlos y gestionar su potencial.

Cómo promover el desarrollo de habilidades y capacidades de los empleados en una empresa.
Para lograr un ambiente laboral favorable para el desarrollo de las habilidades y capacidades de los empleados, es importante considerar los intereses y necesidades individuales de cada uno. Esto incluye aspectos como la motivación, el reconocimiento, la autorrealización, la socialización y la remuneración.
Para alcanzar esta meta, se sugieren las siguientes acciones:
-Fomentar una cultura organizacional positiva y armoniosa.
-Ofrecer oportunidades de crecimiento y desarrollo atractivas para el personal.
-Implementar sistemas de evaluación y retroalimentación para medir y mejorar el desempeño.

Departamento de Comunicación Grupo Hasten
La gestión del talento empresarial